SLAM: la memoria espacial de la máquina
Rubén Rodríguez Abril
SLAM —Simultaneous Localization and Mapping— permite a una máquina orientarse mientras construye un mapa de su entorno. Combina las disciplinas de odometría, mapeo, cierre de bucles y optimización de trayectoria, que examinaremos brevemente en este artículo. Esta síntesis entre geometría y aprendizaje capacita a la mente maquínica para moverse y recordar dónde estuvo.
Introducción
Si en el artículo anterior analizamos los diferentes sensores que aportaban datos a la máquina relativos a su posición y orientación en el espacio, en este artículo abordaremos los algoritmos que estiman pose, movimiento y geometría directamente a partir de los datos sensoriales. Estos algoritmos se agrupan bajo el nombre de SLAM (Symultaneous Location and Mapping, Localización y Mapeo Simultáneos).
En la actualidad, los métodos clásicos (anteriores a la irrupción de la IA) están siendo desplazados por nuevos métodos de aprendizaje profundo, que utilizan redes neuronales artificiales para construir mapas y ofrecer datos relativos a la posición y orientación en el espacio.
El SLAM, particularmente en entornos vehiculares, articula su funcionamiento en cuatro disciplinas fundamentales:
–Mapeo: construye una representación volumétrica y semántica del entorno (mapa), fusionando observaciones sucesivas para crear un modelo coherente del espacio.
–Odometría: estima el desplazamiento y la rotación (pose) del vehículo en el tiempo utilizando datos de sensores visuales, inerciales o LiDAR. La trayectoria del vehículo es representada por un grafo, algunos de cuyos nodos representan las sucesivas poses del mismo.
–Relocalización y cierre de bucles: corrige la deriva acumulada al reconocer ubicaciones previamente visitadas, permitiendo así recuperar la posición exacta tras una pérdida de seguimiento.
–Optimización: ajusta conjuntamente las poses estimadas y la estructura del mapa mediante técnicas de ajuste de grafos, minimizando inconsistencias espaciotemporales.
Las tres primeras reciben el nombre genérico de front-end, y señalan a la máquina dónde se encuentra. La cuarta, la optimización, recibe el nombre de back-end, y ajusta la trayectoria del vehículo y su grafo.
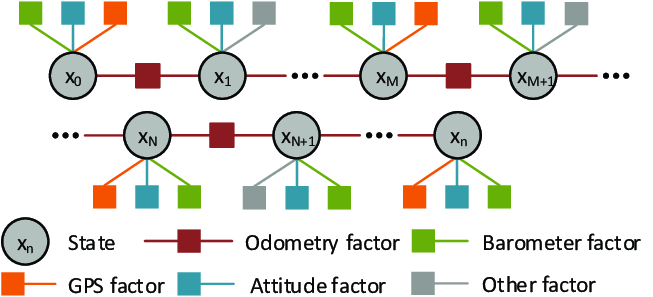
Figura 1. Ejemplo de grafo de poses. Cada nodo de estado xn representa la posición y la orientación del vehículo (6 grados de libertad). Los factores —odometría, GPS, barómetro e inerciales— imponen restricciones entre estados consecutivos y determinan la evolución dinámica del sistema. Fuente: SIMSF: A Scale-Insensitive Multi-Sensor Fusion Framework for Unmanned Aerial Vehicles Based on Graph Optimization.
Mapeo
La construcción de mapas es fundamental para la navegación autónoma. Este proceso integra datos de múltiples fuentes -como LiDAR, cámaras, radar, IMU y GNSS- para generar una representación tridimensional y semántica del entorno.

Figura 2. Nube de puntos LiDAR correspondiente a la intersección de dos calles en la ciudad de San Francisco. Fuente: Wikipedia.
El flujo de trabajo típico avanza desde capturas de cámara u otros sensores hasta la construcción de un modelo espacial completo:
1) Adquisición de Datos: Se capturan los datos crudos de los sensores, como imágenes (monoculares o estéreo), nubes de puntos LiDAR, datos de radar y GNSS. Estos datos constituyen la base de toda la reconstrucción.
2) Mapa de Profundidad (2.5D): A partir de las imágenes, se construye un mapa donde cada píxel, además del color, contiene un valor de profundidad (distancia a la cámara). Ello puede hacerse mediante algoritmos de Deep Learning (estimación de profundidad monocular) o utilizando cámaras de Time-of-Flight (ToF), que miden directamente el tiempo de vuelo de la luz, y en base a ello calculan la distancia.
3) Mapa Volumétrico TSDF (3D): El mapa de profundidad se convierte en una rejilla tridimensional de vóxeles. Mediante procesos como raycasting o TSDF fusion, a cada vóxel se le asigna un valor de distancia con signo (SDF, Signed Distance Field) que indica su proximidad a una superficie: valor cero (en la superficie), positivo (en el espacio libre) o negativo (tras la superficie). Este mapa se actualiza en tiempo real con cada nuevo frame.
4) Mapa Semántico/Panóptico: Sobre la base geométrica del mapa volumétrico, se superpone información de significado. Algoritmos de segmentación semántica 3D o detección de objetos clasifican los vóxeles, asignándoles etiquetas como «peatón», «vehículo» o «calzada».
5) Mapas ESDF (Euclidean Signed Distance Field): Estos mapas miden la distancia entre cada punto del espacio (vóxel) y el obstáculo más cercano. Un valor alto indica que el punto se encuentra en una zona ampliamente despejada —como un «Punto Nemo» local—, mientras que un valor bajo señala proximidad a una superficie. En términos prácticos el TSDF define los relieves, mientras que el ESDF describe el espacio libre que los rodea. En navegación autónoma, se suele definir un campo de potencial repulsivo F(x) = -D (donde D es el valor ESDF), cuyo gradiente, -∇F(x), apunta en la dirección de los obstáculos más cercanos. Esto permite al vehículo calcular trayectorias seguras. alejándose eficientemente de las zonas de riesgo.
6) Mapa Vectorial HD (Offline): Para una navegación de alta precisión, se utiliza un mapa vectorial de alta definición, elaborado offline con exactitud centimétrica. Este mapa vectorial contiene información estática de la vía: geometría de carriles, ubicación de semáforos, señales y curvas.
Odometría
La odometría constituye el núcleo de la percepción del movimiento.
Como se explicó en secciones anteriores, la odometría inercial es el procedimiento que estima la pose actual -posición y orientación- a partir de la pose anterior y los datos sensoriales, estimando el desplazamiento recorrido. Este procedimiento, conocido como integración de ruta (path integration), puede implementarse en distintas modalidades, siendo las más relevantes la odometría inercial pura y la odometría visual-inercial (VIO).
Odometría inercial
En la odometría inercial, las lecturas de aceleración lineal y velocidad angular obtenidas por la unidad de medición inercial (IMU) se integran en el tiempo.
La posición se calcula mediante doble integración de la aceleración —dado que esta es la segunda derivada de la posición—, lo que hace al sistema altamente sensible a errores y sesgos en los sensores. Tradicionalmente, la fusión de estas mediciones y la estimación de la pose se realiza mediante algoritmos como el filtro de Kalman.
Este mecanismo de integración de ruta presenta notables similitudes con el funcionamiento de las células de rejilla (grid cells) en la corteza entorrinal medial del cerebro, descubiertas en 2005. Estas neuronas parecen realizar en el encéfalo de roedores una tarea equivalente a la odometría inercial, permitiéndoles moverse y regresar a su madriguera en completa oscuridad utilizando únicamente señales internas de movimiento. Para ello, las células de rejilla integran información procedente de las células de dirección de la cabeza (head direction cells), que actúan como una brújula interna, y de las células de velocidad (speed cells), que codifican la rapidez del desplazamiento y que constituyen, junto con las anteriores, una suerte de IMU biológica.
En sistemas artificiales, como vehículos y robots, la navegación inercial clásica sigue un principio análogo: las velocidades angulares del giroscopio se integran para obtener orientación, y las aceleraciones del acelerómetro —previo filtrado de la gravedad— para calcular velocidad y posición. Este proceso de doble integración amplifica exponencialmente cualquier sesgo o ruido presente en las señales de los sensores.
El resultado es una deriva acumulativa (drift) que, incluso con errores iniciales pequeños, crece de forma cuadrática en el caso de la posición, haciendo insostenible la navegación puramente inercial a largo plazo.
Para mitigar este problema, recientemente se ha explorado el uso de aprendizaje profundo para perfeccionar métodos de odometría. Como se documenta en el trabajo «Deep Learning for Inertial Positioning: A Survey» de Chen y Pan, estos algoritmos pueden incorporarse en distintos niveles del sistema de navegación:
1. Calibración en línea de sensores inerciales, reduciendo errores procedentes del sesgo, de la temperatura o del ruido.
2. Corrección directa de la integración inercial, aprendiendo a compensar la deriva a partir de los datos crudos de la IMU.
3. Fusión multisensorial, particularmente en sistemas VIO (Visual-Inertial Odometry), donde se combinan datos de la IMU con flujo visual de una cámara para obtener estimaciones más precisas. Este último caso será analizado en el siguiente apartado.
Odometría visual e inercial (VIO)
Los sistemas VIO combinan información visual (de cámaras) con la inercial (de la IMU) para estimar la pose, la velocidad, así como los sesgos de los sensores. Pueden dividirse en dos grandes enfoques: clásicos (geométricos) y aprendidos (basados en deep learning).
VIO clásico
Los sistemas clásicos de VIO, desarrollados antes del auge del deep learning, no utilizan redes neuronales. Su arquitectura se divide en dos flujos de procesamiento principales que luego se fusionan:
– Módulo Visual: Detecta puntos clave en la imagen (como esquinas o bordes) mediante algoritmos artesanales (sin deep learning) y poco costosos computacionalmente, como FAST, ORB o SIFT para la descripción. A estos puntos clave se les realiza un seguimiento a lo largo de los fotogramas del video. No todos los fotogramas se procesan; solo un subconjunto seleccionado, denominado keyframes, es utilizado para calcular el movimiento del vehículo, ahorrando así carga computacional.
– Módulo Inercial (IMU): La Unidad de Medición Inercial proporciona datos de alta frecuencia sobre aceleración lineal y velocidad angular. Dado que su tasa de muestreo es muy superior a la de la cámara, las mediciones de la IMU entre dos keyframes se consolidan mediante un proceso llamado preintegración, garantizando la coherencia temporal entre ambos flujos.
La pose de la máquina (su posición y orientación en el espacio) se estima de forma sincronizada por ambos módulos cada vez que se procesa un nuevo keyframe. Cuando los datos visuales (de la cámara) y las inerciales (de la IMU) presentan discrepancias, un algoritmo de optimización no lineal (como el de Gauss-Newton o Levenberg-Marquardt) ajusta iterativamente todos los parámetros del sistema (las poses sucesivas y las posiciones de los puntos de referencia), con el objetivo de minimizar dichas diferencias. Este proceso busca la configuración global que mejor explique de forma coherente todas las mediciones de los sensores. Es análogo a la minimización de la función de pérdida en el entrenamiento de una red neuronal. Este proceso será detallado por la última sección de este artículo.
Cada medición proveniente de los sensores está ponderada por una matriz de covarianza que cuantifica la confianza del sistema en ese dato específico. Una covarianza grande indica alta incertidumbre, por lo que el optimizador «hará menos caso» a esa medición, mientras que una covarianza pequeña le dará un peso mayor en la solución final. Este mecanismo permite equilibrar automáticamente la influencia de la cámara y la IMU según su fiabilidad en cada instante.
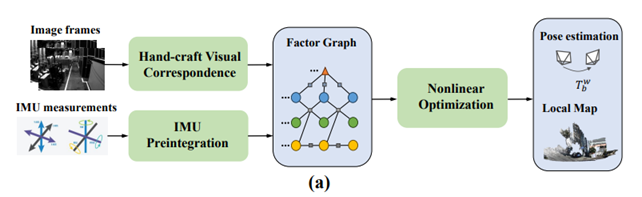
Figura 3. Esquema del funcionamiento de un algoritmo clásico de odometría visual inercial. Un algoritmo “artesanal” (no basado en el deep learning) detecta puntos de referencia en los fotogramas de la cámara, y los “persigue” a lo largo del tiempo. Un procedimiento de preintegración asegura que los datos inerciales se sincronicen con los de la cámara, más lenta. El cálculo de las sucesivas poses se expresa mediante un grafo de factores, en el que los datos visuales e inerciales, así como las sucesivas poses, se representan como nodos del grafo. Finalmente, un algoritmo de optimización modifica los parámetros con el objetivo de que haya la menor discrepancia posible entre datos inerciales y visuales. Fuente: Adaptive VIO: Deep Visual-Inertial Odometry with Online Continual Learning.
.
VIO basado en el deep learning (de extremo a extremo)
Los sistemas de VIO (Odometría Visual Inercial) clásicos presentan limitaciones significativas en cuanto a robustez. A menudo son sensibles a movimientos bruscos de la cámara, variaciones abruptas de iluminación, condiciones meteorológicas adversas (como niebla o lluvia) o a la deriva acumulativa provocada por el sesgo de las Unidades de Medición Inercial (IMU).
Para abordar estos desafíos, recientemente se han propuesto arquitecturas multimodales de deep learning que calculan la pose de la plataforma de manera directa. Se trata de redes neuronales artificiales que, por lo general, tienen la estructura siguiente:
– Codificador de Imagen: Una red neuronal convolucional (CNN) se encarga de extraer características visuales significativas de cada fotograma. La salida de este módulo es un tensor de tres dimensiones (alto, ancho, canales), que codifica la información espacial y semántica de la escena.
– Codificador Inercial: Este módulo procesa las lecturas crudas de la IMU (acelerómetro y giroscopio) a lo largo de una ventana temporal. Mediante capas densas o recurrentes, transforma esta secuencia de datos en un vector de embedding compacto.
– Red de Fusión: Es el núcleo del sistema y toma como entrada los embeddings provenientes de los codificadores visual e inercial. A menudo, se implementa como una red recurrente (como una LSTM o GRU), que también recibe como entrada su estado inmediatamente anterior. En cada paso temporal, la red estima la pose relativa de 6 grados de libertad (6-DoF), típicamente representada como un vector de posición (coordenadas XYZ) y otro de orientación (generalmente en ángulos de Euler).
A pesar de su prometedor enfoque, estos métodos basados en deep learning adolecen de una limitada capacidad de generalización. Su rendimiento es a menudo inferior al de los métodos clásicos en escenarios conocidos y se degrada significativamente cuando se enfrentan a entornos o circunstancias no vistas durante el entrenamiento, como cambios radicales en la textura del entorno, iluminación o tipos de movimiento.
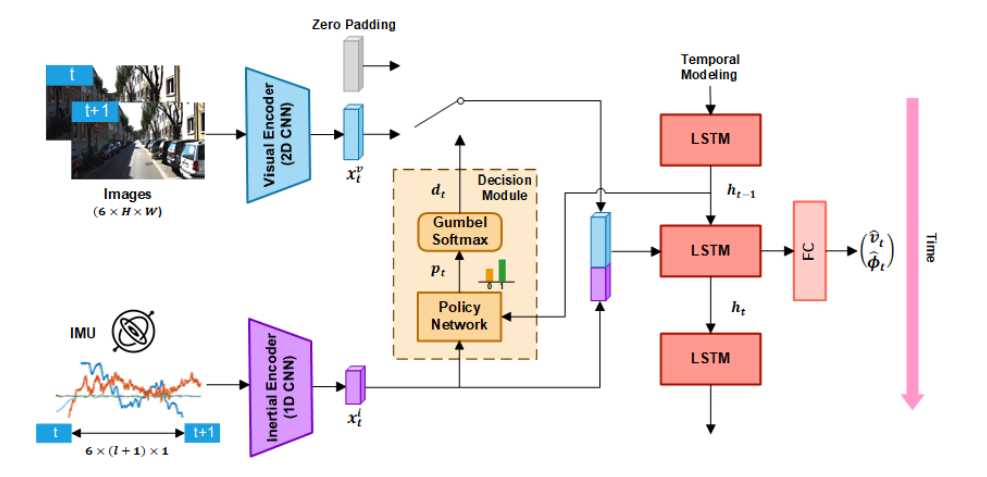
Figura 4. En este ejemplo, el codificador visual es una red convolucional de dos dimensiones, mientras que el codificador inercial consiste en una convolución de una dimensión que actúa sobre los datos del giróscopo y el acelerómetro. Ambos vectores se concatenan y alimentan una LSTM, cuya salida es el vector que expresa la pose. Fuente: Efficient Deep Visual and Inertial Odometry with Adaptive Visual Modality Selection.
Cierre de bucle y relocalización
Los errores acumulados de la odometría, generados por múltiples causas, se denominan deriva, y pueden conducir a que la máquina pierda la noción precisa de su ubicación. Para mantener la cohesión del mapa global se incorporan dos mecanismos complementarios:
–Cierre de bucles: Se activa cuando el sistema reconoce un lugar previamente visitado.
–Relocalización global: Entra en juego cuando la localización se pierde por completo y es necesario reiniciar el proceso de SLAM.
Cierre de bucle
Este proceso ocurre cuando la máquina percibe que ha regresado a una ubicación ya registrada. Al confirmar la coincidencia se actualiza no sólo la pose actual, sino también, retroactivamente, toda la trayectoria anterior. Es una suerte de deja vú maquínico.
El flujo del proceso es el siguiente:
1) Generación y comparación de descriptores globales
Periódicamente, el sistema genera descriptores globales para las escenas clave (keyframes). Estos descriptores son vectores compactos que codifican la esencia de una escena, sintetizando información visual (cámaras), láser (LiDAR) y de otros sensores. Algoritmos como NetVLAD, citado en el apartado anterior, permiten crear estos identificadores únicos, capaces de caracterizar un lugar de forma robusta.
2) Detección y verificación de bucles
Cada nuevo descriptor se compara en tiempo real con los almacenados en la base de datos histórica. Si la similitud de ambos supera un umbral de confianza, se activa un proceso ulterior de verificación geométrica mediante métodos como ICP, RANSAC o PnP, que alinean las observaciones actuales con el mapa preexistente para confirmar la coincidencia espacial.
3) Corrección de la deriva acumulativa
Una vez validado el bucle, el sistema impone una nueva restricción al grafo de poses, que conecta la posición actual con la pose histórica reconocida. Esa restricción conlleva a una corrección retroactiva de la deriva acumulada a lo largo de toda la trayectoria.
Relocalización global
Este mecanismo se activa ante una pérdida catastrófica de localización, generalmente provocada por:
– Oclusión sensorial (ej: túneles que interrumpen señales de GPS, cámaras o LiDAR).
– Movimientos bruscos que superan la capacidad de seguimiento de la odometría visual o inercial.
El sistema compara el descriptor actual con todos los registros del mapa global (no solo con ubicaciones recientes). Al encontrar una coincidencia válida, reconstruye el grafo de poses desde cero, reubicando al vehículo en el mapa preexistente. La trayectoria se reinicializa y el proceso de SLAM se reanuda integrando nuevas observaciones al contexto recuperado.
La capacidad de relocalización es crucial para scenarios donde el vehículo «pierde el hilo» por fallos sensoriales prolongados, permitiéndole reintegrarse al mapa sin requerir una reinicialización manual del sistema.
Optimización: El juste final del mapa y la trayectoria
Si el front-end del SLAM (mapeo, odometría y cierre de bucles) es el sistema nervioso que percibe y registra el entorno, el back-end de optimización es el cerebro que corrige y consolida esos datos en un modelo coherente. Su función es resolver las contradicciones acumuladas, ajustando de forma conjunta la trayectoria estimada del vehículo y la estructura del mapa.
El grafo de poses: la columna vertebral del SLAM
El sistema representa toda la historia de la exploración como un grafo de poses. En este grafo:
– Cada nodo es una pose concreta del vehículo en un instante de tiempo (su posición y orientación).
– Cada arista es una restricción que actúa como un vínculo físico entre dos poses, imponiendo una condición de proximidad espacial. Estas restricciones surgen de dos fuentes clave:
1. La odometría: Conecta poses consecutivas (Pose 1 → Pose 2), fusionando datos de sensores como IMU, GNSS y cámaras para restringir el movimiento incremental. Codifica las leyes del movimiento entre dos instantes consecutivos de tiempo.
2. El cierre de bucles: Conecta dos nodos distantes (Pose 5 ↔ Pose 105), revelando que representan la misma ubicación física y forzándolas a coincidir para corregir la deriva acumulada.
El proceso de optimización: ajustando el grafo
El objetivo del back-end es encontrar la configuración de todos los nodos del grafo que mejor satisfaga el conjunto de restricciones.
Algoritmos no lineales como Gauss-Newton o Levenberg-Marquardt son los encargados de resolver este problema, «deformando» suavemente todo el grafo para distribuir el error y lograr un mapa y una trayectoria globalmente consistentes. El error es distribuido a lo largo de toda la estructura.
La optimización no se ejecuta en cada marco (frame), sino de forma periódica o cuando se detecta un evento significativo (como un cierre de bucle). El front-end opera en tiempo real, mientras el back-end trabaja en paralelo, refinando constantemente el grafo de poses.
Desafíos
El principal desafío de los métodos de SLAM es la escalabilidad. La complejidad de optimizar un grafo con miles de nodos puede ser prohibitiva. Para paliar este problema se emplean técnicas avanzadas como:
– iSAM2 (Incremental Smoothing and Mapping): Actualiza la solución de forma incremental sin recomputar todo el grafo.
– Optimización Jerárquica: Divide el mapa en submapas que se optimizan localmente y luego se ensamblan globalmente.
Conclusión
El SLAM constituye la base cognitiva de la navegación autónoma, permitiendo a la máquina construir un modelo espacial coherente del mundo mediante la combinación de percepción sensorial, memoria y corrección continua. A través de la fusión de odometría, mapeo y optimización, el sistema no solo se ubica con precisión en su entorno, sino que adquiere la capacidad fundamental de tomar decisiones autónomas sobre su movimiento. Esta tecnología representa el núcleo de la mayoría de los sistemas de conducción sin piloto existentes en la actualidad, desde drones hasta vehículos terrestres.
SERIES







