
La fotónica de silicio y el advenimiento del Umbral Óptico
Rubén Rodríguez Abril
El término «Umbral Óptico» describe el punto de inflexión en el que las Unidades de Procesamiento Óptico (OPUs) —prometedoras por su eficiencia térmica al computar con luz— alcancen adopción masiva en el campo del Deep Learning. Este viraje tecnológico puede reconfigurar la geopolítica de los semiconductores: el liderazgo dejará de depender exclusivamente de la miniaturización extrema (litografía EUV) para radicarse en el dominio de la integración optoelectrónica, abriendo así el juego a una gama más amplia de actores.
Introducción
Durante más de una década el aprendizaje profundo ha vivido bajo el imperio absoluto de las GPUs. Desde el año 2011 en adelante, los procesadores gráficos se transformaron en el hardware básico en torno al cual se articularon los sistemas de visión artificial o los grandes modelos de lenguaje. Con el paso del tiempo, el escalado de los modelos y la ampliación de las capacidades de la inteligencia artificial se ha realizado a través del empleo de más transistores, más núcleos y más vatios.
Pero este escalado se asienta sobre una fisura fundamental: su voracidad energética. Los centros de datos, que son el sistema nervioso de la IA moderna, ya consumen cerca del 1% de la demanda eléctrica global. En Estados Unidos, se proyecta que esta cifra alcance un asombroso 9% para el año 2030, una tendencia que amenaza con volverse insostenible.
La asfixia térmica del Aprendizaje Profundo
En la actualidad, la termodinámica del aprendizaje profundo es extremadamente ineficiente. Solo una fracción del consumo eléctrico total (que casi en su totalidad se disipa en forma de calor) se dedica a las operaciones aritméticas útiles, mientras que la mayor parte se invierte en movimiento de datos, memoria, control e interconexión. A esta ineficiencia se suma el coste energético de la refrigeración de los centros de datos, que incluso en instalaciones avanzadas supone del orden del 15–25 % del consumo total, y que puede superar el 40 % en escenarios de alta densidad térmica. El resultado es una espiral en la que una parte creciente del presupuesto energético se destina únicamente a gestionar el calor generado por el propio cómputo, estrangulando la escalabilidad y la rentabilidad del paradigma digital convencional.
La IA necesita, con urgencia, un nuevo soporte físico.
El Umbral Óptico
Entre todas las tecnologías alternativas, la computación óptica —y sus OPUs, Optical Processing Units—acumula ya las señales concretas de una disrupción inminente. Su principio de operación permite la realización masiva de cómputos paralelos mediante interferencia de luz, generando menos calor que los circuitos integrados en varios órdenes de magnitud.
Para que esta tecnología se generalice, debe producirse el equivalente óptico de la convergencia de factores que, a finales de la década de los 2000, catalizó la transición hacia las GPUs en el aprendizaje de máquina. Este periodo crítico —al que denominaremos Umbral Óptico— no será un evento aislado, sino el resultado de un cóctel bien definido consistente en la maduración de arquitecturas de procesador óptico, la demostración incontestable de su utilidad en tareas reales de visión artificial o procesamiento de lenguaje natural, la superación de los cuellos de botella en su escalado industrial y la integración de ecosistemas de software que transformen los prototipos de laboratorio (como Envise o Meteor 1) en componentes fiables, económicos y aptos para la producción masiva. La adopción por parte de hiperescaladores será, como ocurrió con las GPUs, el último paso que confirme el cruce definitivo de este umbral.
El antecedente: la transición del Deep Learning a las GPUs (2006-2011)
La generalización de las GPUs como soporte físico del deep learning tuvo lugar como consecuencia de la acumulación temporal de varios eventos decisivos en un periodo de tiempo de apenas 5 años:
-La aparición de la plataforma CUDA.
-La llegada de DanNet (una CNN entrenada plenamente en GPUs de uso general).
-Los trabajos experimentales del equipo de Andrew Ng.
Surgimiento de la plataforma e interfaz CUDA (2007)
En el año 2007 NVIDIA lanzó su interfaz CUDA, que transformó a la GPU de un simple acelerador de gráficos, usado primordialmente en simulaciones y gaming, en un procesador de propósito general programable. Antes de CUDA, programar una GPU para tareas no gráficas era una hazaña de ingeniería inversa. CUDA proporcionó el compilador, las librerías y la abstracción necesarias para que los investigadores trataran a la GPU como lo que era: una máquina de cálculo que operaba en paralelismo masivo. Tras la llegada de CUDA, los procesadores gráficos fueron adoptados masivamente en la computación de alto rendimiento y en IA.
Aparición de DanNet (2011)
En 2011, DanNet —una red neuronal convolucional (CNN) profunda desarrollada por el estudiante Dan Cireșan y su equipo— desencadenó la revolución del deep learning visual al ganar cuatro competiciones consecutivas. Su clave fue una implementación ultrarrápida en GPUs NVIDIA, que permitió acelerar extraordinariamente el proceso de entrenamiento y logró el primer rendimiento superhumano en visión artificial ese mismo año. Este éxito práctico demostró la superioridad de las CNNs profundas en este campo y preparó el terreno para avances posteriores como AlexNet (2012) o las redes con cientos de capas (Highway Nets, ResNet).
Adopción en centros de datos para IA: Andrew Ng (2008-2009)
Andrew Ng y su equipo aportaron el argumento económico. Demostraron que modelos que consumían miles de núcleos de CPU podían ejecutarse eficientemente en clústers muchos más pequeños de GPUs. Convenció a la industria de que el futuro escalable del deep learning no pasaba por expandir las granjas de servidores de CPU, sino por rediseñar la infraestructura alrededor de la arquitectura paralela de las GPUs.
La fotónica de silicio (Silicon Photonics, SiPh): base industrial de los futuros procesadores ópticos
El salto a las GPUs descrito en la sección anterior fue posible porque existía ya un sustrato industrial desarrollado desde finales de los años cincuenta, basado en la electrónica de silicio, los circuitos integrados y procesos CMOS maduros.
En el ámbito de la computación óptica, la fotónica de silicio (Silicon Photonics, SiPh) desempeña un papel análogo al de la microelectrónica en las GPUs. Se trata de un conjunto de técnicas que permite implantar directamente sobre obleas de silicio los componentes fundamentales de los sistemas ópticos —guías de onda, moduladores y detectores— utilizando herramientas, flujos y escalas heredadas de la microelectrónica.
Impulsada por la creciente demanda de interconexión de alta velocidad en HPC e inteligencia artificial, la fotónica de silicio se encuentra en plena transición desde la I+D hacia la adopción comercial masiva. Su valor no reside únicamente en transmitir información mediante fotones en lugar de electrones, sino en hacerlo de forma fabricable, repetible y económicamente viable, abriendo por primera vez la puerta a chips ópticos producidos a escala. Si logra superar los retos restantes de integración y fabricación, la SiPh no solo constituirá la base física de los futuros procesadores ópticos, sino que transformará sectores como los centros de datos —al aliviar el cuello de botella en la comunicación entre servidores y racks—, las telecomunicaciones, la inteligencia artificial, el lidar o la biosensórica.
A nivel de dispositivo, la fotónica de silicio permite integrar en un solo chip varios elementos clave: guías de onda, que actúan como “cables de luz”; moduladores, que convierten señales eléctricas en ópticas; fotodetectores, que realizan la conversión inversa; y acopladores, que en procesadores ópticos basados en interferómetros de Mach–Zehnder (como Meteor-1 o Envise) permiten introducir información en la luz mediante la modificación de su fase.
En la actualidad, gran parte del impulso industrial de la SiPh proviene de la óptica coempaquetada (co-packaged optics, CPO), una estrategia que sitúa componentes ópticos (p.e. extremos de un cable de fibra) y chips electrónicos de cómputo (ASICs) dentro de un mismo paquete avanzado para reducir distancias eléctricas, ahorrar energía y aumentar el ancho de banda en centros de datos. En estos sistemas, óptica y electrónica todavía siguen siendo bloques funcionales diferenciados que se ensamblan a nivel de empaquetado.
El objetivo último, sin embargo, es más ambicioso: la fotónica de silicio de un solo chip, en la que componentes ópticos y electrónicos se sitúen de forma monolítica sobre una misma oblea de silicio —y no únicamente dentro de un mismo paquete. Esta integración permitiría alcanzar niveles inéditos de miniaturización, eficiencia energética y reducción de costes, al tiempo que promete aliviar el cuello de botella estructural existente entre el dominio óptico y el electrónico (que dificulta la transferencia de datos entre ambos ámbitos).
De lo que se trata no es sólo de interconectar mejor los sistemas existentes en un centro de datos, sino de fundir en un mismo chip las operaciones ópticas —multiplicaciones matriciales— con los bloques electrónicos necesarios para la no linealidad, el control y la memoria a corto plazo. Mientras la óptica coempaquetada (CPO) se centra en mejorar el empalme entre fibra óptica y ASICs, la fotónica de silicio monolítica abre la vía al diseño y al escalado industrial de OPUs como una nueva clase de procesadores.

Figura 1. Imagen del chip Envise. Fuente: Universal photonic artificial intelligence acceleration.
Dos grandes desafíos: del umbral experimental al umbral industrial
[Nota: Envise y Meteor 1 son los dos grandes prototipos de procesador óptico surgidos en 2025. Ambos tienen su artículo dedicado en La Máquina Oráculo]
La fotónica de silicio monolítica establece, por primera vez, una base física viable para la fabricación de procesadores optoelectrónicos. Sin embargo, disponer de una tecnología habilitadora no es suficiente para cruzar el Umbral Óptico. Para que los procesadores basados en luz abandonen definitivamente el laboratorio y se conviertan en infraestructura computacional, deben superar dos desafíos de naturaleza distinta, pero igualmente críticos.
El primero consiste en demostrar su superioridad computacional y energética de forma incuestionable en el plano experimental.
El segundo exige convertir ese logro en un producto fabricable y escalable industrialmente, superando los cuellos de botella que todavía afectan a la fotónica integrada.
El experimento óptico decisivo
La promesa teórica de la computación óptica —eficiencia energética extrema, paralelismo masivo y latencias ultrabajas— debe materializarse en una demostración práctica concluyente: un experimento reproducible en el que una OPU ejecute una parte nuclear de un modelo de deep learning real con ventajas medibles y decisivas frente al estado del arte electrónico.
Un hito de este tipo debería cumplir, como mínimo, cinco condiciones:
- Modelo y tarea reales.
Ejecución de bloques fundamentales de modelos de producción como BERT, ViT o LLaMA (por ejemplo, una capa completa de autoatención o un perceptrón multicapas).
- Ventaja contundente en métricas clave.
Mejora de al menos 3× en eficiencia energética (TOPS/W) y 2× en throughput (computación por segundo) frente a aceleradores punteros como NVIDIA H100 o AMD MI300X.
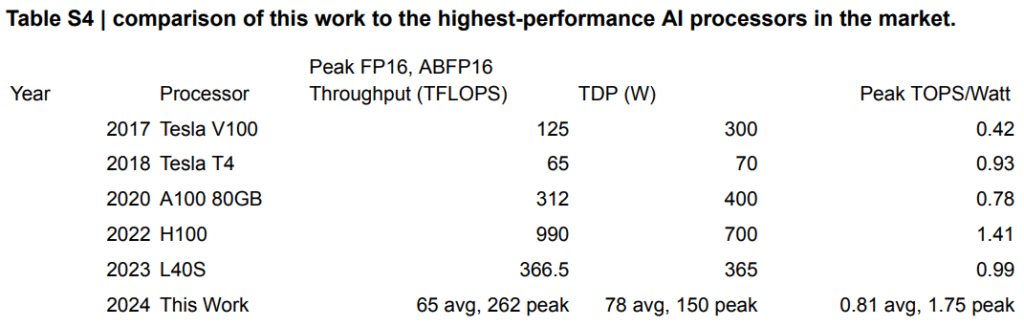
Figura 2. La capacidad computacional (throughput) de Envise (65 TOPS de media) en ABFP16 es aun muy inferior a la de NVIDIA H100 en FP16. Además, Envise tiene una menor eficiencia térmica media (0,81 TOPS/W), en términos de TOPS por vatio. Con todo, estas comparaciones ignoran la diferencia de madurez tecnológica: mientras la H100 representa el ejemplo más avanzado de una arquitectura digital optimizada durante décadas, las OPUs actuales son exponentes de un régimen computacional distinto, que aun sigue en fase de desarrollo. Fuente: Universal photonic artificial intelligence acceleration (Envise).
- Precisión útil.
Una degradación de la precisión no superior al 5-10 %, asumible en escenarios reales de inferencia.
- Comparación directa y honesta.
La referencia debe ser siempre la GPU líder del momento, no CPUs ni arquitecturas obsoletas.
- Existencia de interfaces de programación.
Disponibilidad de un stack de software accesible —con APIs para PyTorch o JAX— para los programadores.
Un experimento de estas características constituiría el equivalente óptico al momento en que Dan Cireșan demostró que una GPU de consumo podía entrenar redes convolucionales profundas en días, y no en meses.
Los cuellos de botella del escalado industrial
Un experimento brillante, si se queda en un mero prototipo de laboratorio, no desencadenará por sí solo una disrupción tecnológica. El segundo gran requisito para cruzar el Umbral Óptico es la transición desde dispositivos experimentales hacia procesos de fabricación monolíticos, repetibles y fiables, capaces de integrar óptica y electrónica en un único chip.
La viabilidad industrial de las OPUs depende de superar una serie de bloqueadores específicos de la fotónica integrada, entre los que destacan los siguientes:
Testeo y aprendizaje de yield.
En microelectrónica existen metodologías maduras para identificar no solo el porcentaje de chips exitosos (yield) y defectuosos, sino también las causas del fallo y las regiones responsables (aprendizaje de yield). En fotónica integrada, el testeo sigue siendo lento, costoso y con escasa capacidad de diagnóstico espacial.
Variabilidad no controlada entre dispositivos.
El despliegue industrial de las OPUs choca con un problema fundamental: la escasa uniformidad entre dispositivos fabricados. Mientras que la producción en masa exige un comportamiento estadísticamente predecible, la dispersión en los parámetros clave de los chips ópticos sigue siendo significativa.
Ausencia de criterios industriales de binning (clasificación por calidad).
Mientras que en electrónica existen clasificaciones estandarizadas (consumo, industrial, automotriz), en fotónica integrada no hay aún criterios consensuados para clasificar chips según pérdidas ópticas, diafonía o tolerancias, lo que impide un mercado de componentes interoperables.
Gestión térmica y aparición de hotspots.
La integración monolítica de componentes ópticos y electrónicos introduce nuevos desafíos térmicos. Aunque el cálculo óptico genera menos calor que su equivalente electrónico, los bloques electrónicos asociados —drivers, DACs, ADCs y lógica de control— pueden crear hotspots locales que degradan el rendimiento y la fiabilidad de moduladores, detectores y guías de onda sensibles a la temperatura. La gestión térmica a escala micrométrica se convierte así en un requisito crítico para la estabilidad, el envejecimiento y la vida útil de los chips optoelectrónicos.
Fiabilidad y certificación de vida útil.
No existen aún protocolos equivalentes a JEDEC para caracterizar estrés térmico, humedad o envejecimiento de componentes optoelectrónicos integrados, especialmente en arquitecturas híbridas donde conviven dominios con tolerancias físicas muy distintas.
La electrónica de silicio ha dedicado más de cinco décadas a resolver estos problemas mediante control estadístico de procesos, testeo automatizado y estandarización industrial. La fotónica de silicio monolítica, en su camino hacia las OPUs como nueva clase de procesador, debe resolverlos de forma simultánea y en arquitecturas intrínsecamente más sensibles.
Primeros ámbitos de aplicación de las OPUs: inferencia de baja precisión, alta eficiencia
[Nota: Recomendamos consultar la sección «Modificación de formatos numérico» del artículo enlazado con el propósito de obtener una breve explicación de la cuantización, que permite que modelos funcionen en inferencia con una aritmética de INT4 o INT8, a pesar de haber sido entrenados en FP16]
La adopción comercial de las Unidades de Procesamiento Óptico (OPUs) no dependerá de que igualen la precisión de 64 bits de las GPUs digitales. Por el contrario, su irrupción se producirá en el vasto mercado de la inferencia de inteligencia artificial de baja precisión y alta tolerancia al error, donde podrán ofrecer un throughput masivo y una eficiencia energética sin precedentes. En este contexto, INT4 es ya plenamente accesible para arquitecturas ópticas actuales, mientras que INT8 constituye un objetivo inmediato gracias a formatos numéricos híbridos como ABFP16.
La razón es física y algorítmica a la vez. La naturaleza intrínsecamente analógica —y por tanto ruidosa— de los multiplicadores matriciales ópticos encaja de forma natural con operaciones de baja precisión. Mientras que un error mínimo en aritmética de coma flotante de alta resolución resulta inaceptable en simulaciones científicas, la inferencia en visión artificial, procesamiento del lenguaje natural o sistemas de recomendación es notablemente robusta al ruido. Estos modelos, cuantizados masivamente a INT8 y de forma creciente a INT4, sacrifican una fracción imperceptible de precisión a cambio de aumentos drásticos en velocidad, reducción del tamaño del modelo y ahorro energético. En este régimen, una OPU no necesita ser perfecta: necesita ser abrumadoramente más eficiente dentro de un margen de error permisible.
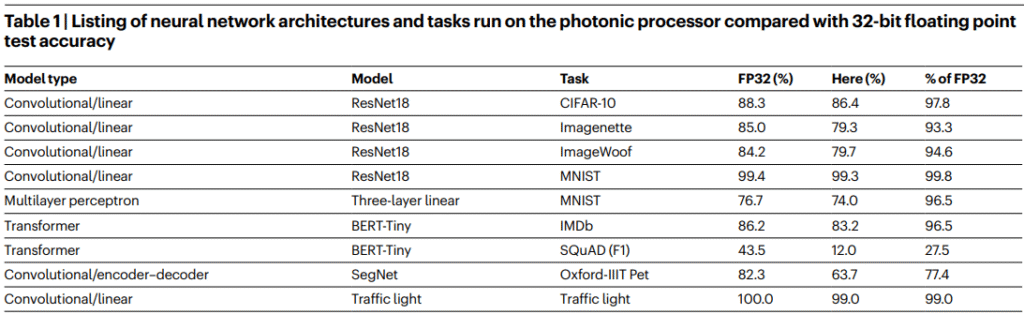
Figura 4. Desempeño del chip Envise y su aritmética ABFP16 en comparación con la aritmética FP32 para diferentes modelos. En el caso de ResNet18 y Traffic Light la exactitud (accuracy) de ABFP16 es casi tan alta como la de FP32. Fuente: Universal photonic artificial intelligence acceleration (Envise).
Esta tolerancia no es una hipótesis teórica, sino un resultado experimental. En el trabajo de presentación de Meteor 1, sus diseñadores mostraron que incluso con una consistencia del 90 % en las operaciones ópticas —aceptando, por tanto, un nivel significativo de variabilidad— la accuracy de una red neuronal convolucional apenas descendía en torno a un 2,5 % en tareas de clasificación visual (MNIST). Este resultado pone de manifiesto un hecho fundamental: las redes neuronales profundas no solo toleran el ruido computacional, sino que han sido entrenadas desde su origen sobre señales intrínsecamente ruidosas. Las entradas visuales procedentes de cámaras, afectadas por iluminación, desenfoque o sensores imperfectos, y las entradas lingüísticas, plagadas de errores tipográficos, ambigüedad y variación humana, definen un entorno donde la precisión absoluta no es el objetivo dominante.
A esta robustez estructural se suma una ventaja algorítmica decisiva: los modelos pueden entrenarse explícitamente para operar en estos regímenes mediante Quantization-Aware Training (QAT). En QAT, el modelo se entrena incorporando desde el inicio los efectos de cuantización y ruido, ajustando sus pesos para compensar imprecisiones sistemáticas del hardware. Este enfoque permite no solo tolerar la baja precisión, sino explotarla, adaptando el comportamiento del modelo a las características físicas del sistema óptico. En este sentido, el ruido deja de ser un efecto colateral y pasa a formar parte intrínseca del diseño conjunto hardware–software.
Desde el punto de vista tecnológico y de mercado, esta convergencia explica por qué la adopción de las OPUs se producirá antes en inferencia que en entrenamiento. El entrenamiento sigue requiriendo una precisión más alta, gradientes estables y una dinámica numérica estricta que hoy favorece a las GPUs digitales. La inferencia, en cambio, es un dominio inherentemente más tolerante, repetitivo y sensible al coste energético, donde INT4/INT8 y QAT ya son prácticas industriales consolidadas. Es ahí donde las OPUs pueden integrarse como aceleradores especializados sin exigir una reconfiguración completa del pipeline de aprendizaje.
En consecuencia, los primeros ámbitos de adopción masiva de las OPUs se situarán en los centros de datos de hiperescaladores y en el edge computing, descargando tareas de inferencia donde hoy dominan las GPUs cuantizadas. Aplicaciones como la clasificación y detección de vídeo en tiempo real, los asistentes de voz, los motores de recomendación o el análisis de datos de sensores para IoT no requieren FP64, sino un rendimiento extremo y eficiente en INT4/INT8. Es precisamente en este régimen —en este umbral de precisión tolerable— donde la computación óptica está llamada a lograr su primera victoria comercial.
Impacto geopolítico del advenimiento del Umbral Óptico
Una nueva realidad técnica: OPUs, una fabricación con reglas distintas
La fabricación de GPUs punteras y de OPUs (Unidades de Procesamiento Óptico) responde a lógicas industriales profundamente distintas. En el ámbito de las GPUs, el liderazgo tecnológico está íntimamente ligado al control de las técnicas de miniaturización extrema (nodos de 3 a 5 nm), entre ellas la litografía ultravioleta extrema (EUV), que hoy por hoy es inaccesible para China debido a las sanciones impuestas por EEUU.
Pero las OPUs basadas en fotónica de silicio operan sobre un soporte físico diferente. Debido a la longitud de onda relativamente amplia de la radiación infrarroja, los componentes críticos de los procesadores ópticos —guías de onda, moduladores e interfaces optoelectrónicas— presentan escalas geométricas mucho más grandes, del orden de cientos de nanómetros a micras, plenamente compatibles con procesos DUV maduros y ampliamente disponibles (p.e. 65 nms). En consecuencia, el peso del progreso técnico no recae tanto en la miniaturización de los transistores como en la precisión geométrica, la uniformidad del proceso, la baja pérdida óptica, la estabilidad térmica y la integración controlada de materiales como el germanio.
Este cambio de régimen técnico es estratégicamente relevante. A diferencia de las GPUs, las OPUs tempranas no requieren nodos lógicos extremos ni litografía EUV para aportar valor en tareas reales, especialmente en inferencia cuantizada (INT4/INT8), donde la tolerancia al ruido y a la aproximación es mayor. El Umbral Óptico introduce así una vía de progreso en la que el rendimiento no depende de reducir transistores, sino de dominar la integración optoelectrónica y el proceso industrial.
Consecuencias estratégicas: un tablero geopolítico reconfigurado
La adopción de la fotónica de silicio monolítica y de las OPUs alteraría la geopolítica de los semiconductores al desplazar los puntos de apalancamiento crítico. El centro de gravedad dejaría de residir exclusivamente en la fabricación de nodos extremos —actualmente dominada por Taiwán a través de TSMC y la litografía EUV de ASML— para repartirse entre nuevas capas del stack tecnológico: arquitecturas ópticas, propiedad intelectual fotónica, PDKs, metrología, testeo, calibración y fiabilidad a largo plazo de sistemas optoelectrónicos integrados.
Esto no implica la desaparición del liderazgo de TSMC ni del ecosistema EUV, pero sí la pérdida de su exclusividad como condición necesaria del rendimiento computacional. En el contexto de las OPUs, el tamaño del nodo deja de ser el factor dominante, y con ello se amplía el conjunto de países capaces de competir en componentes estratégicos del cómputo avanzado.
Para China, este cambio en los paradigmas tecnológicos representa una oportunidad estratégica, si bien no necesariamente le otorga una posición dominante a corto plazo. La arquitectura de las Unidades de Procesamiento Óptico (OPUs) actuales, que recurren a componentes electrónicos fabricados en procesos maduros de unos 65 nanómetros, aligera la desventaja que supone carecer de acceso a la litografía ultravioleta extrema (EUV). Este escenario le permite aprovechar y potenciar su robusta capacidad industrial en la producción de semiconductores en nodos superiores a 28 nm, un segmento donde China ya posee una participación significativa a nivel global.
No obstante, la contienda por el liderazgo en la próxima era de la computación óptica se decidirá en un terreno completamente nuevo y más complejo, donde ni China ni ningún otro país parte con una ventaja clara. Los verdaderos desafíos —y la clave para una ventaja sostenible— residen en dominar campos emergentes como la madurez de la fotónica de silicio monolítica, el control preciso del rendimiento (yield) en la fabricación fotónica, y lograr una integración optoelectrónica estable y eficiente. Superar estas barreras técnicas, más que la mera miniaturización de transistores, definirá a los líderes de la próxima generación computacional.
Para otros actores con fortalezas específicas —como Japón en materiales y fiabilidad, o la Unión Europea en investigación de procesos— el Umbral Óptico incrementa su relevancia sistémica y favorece un escenario más multipolar, en el que el poder no se concentra en un único cuello de botella tecnológico.
En resumen, la irrupción de las OPUs no elimina el actual equilibrio geopolítico de los semiconductores, pero sí lo modifica. La carrera deja de ser unidimensional —centrada en el nodo más pequeño— y pasa a librarse en un terreno más distribuido, donde dominar el proceso optoelectrónico completo puede resultar tan decisivo como, en la era digital, dominar la miniaturización extrema.
La partida por la supremacía computacional inaugura un nuevo tablero.
Lecturas Recomendadas
– ¿Es la IA consciente? (II): silicio, luz y matemática pura. Un artículo de La Máquina Oráculo que explora la posibilidad de que los procesadores ópticos alberguen consciencia y qualia.
– Silicon Photonics CPO Nears Mass-Production Breakthrough?
– “Optical” Breakthrough: Silicon Photonics Chips Ready to Launch.
SERIES





