
El amanecer de la computación óptica
Rubén Rodríguez Abril
La computación óptica promete superar los límites del silicio mediante interferómetros de Mach-Zehnder (MZI) y moduladores espaciales de luz (SLM), capaces de realizar operaciones lineales con una eficiencia energética sin precedentes. No obstante, aún enfrenta cuellos de botella electro-ópticos (ADC/DAC), problemas de calibración y deriva térmica, y la ausencia de un ecosistema de software maduro. Su éxito dependerá de la llegada de proyectos solventes que demuestren de forma irrefutable su superioridad sobre las GPUs.
Introducción
En la actualidad, todo indica que el deep learning basado en los chips de silicio está aproximándose a sus límites de escalabilidad. La ralentización de la ley de Moore, la crisis térmica generada por el fin de la Ley de Dennard hacia 2005-2006, las limitaciones impuestas por los principios de la mecánica cuántica (entre ellos, el efecto túnel) y los enormes desafíos en la fabricación de chips en nodos inferiores a 7 nms, han confluido en un mismo punto: el paradigma electrónico tradicional está agotando su camino de crecimiento.
Ante este escenario, se multiplican los esfuerzos por trasladar parte del procesamiento al dominio óptico, donde la información se manipula y los cálculos se realizan mediante luz en lugar de electrones. En el estado de la técnica del año 2025, la fotónica ha impactado de un modo desigual a los diferentes niveles del deep learning. Mientras que la implementación óptica de funciones no lineales y de celdas de memoria continúa es fase experimental, las transformaciones lineales -base de las operaciones matriciales- han alcanzado un grado de madurez notable: en ellas los cálculos son realizados por los patrones de interferencia de la luz monocromática y coherente (típicamente de láser).
Tensor cores ópticos
En este artículo analizaremos dos métodos cálculo matricial en particular: Las interferómetros de Mach-Zehnder (Mach-Zehnder Interferometers, MZIs) y las moduladores espaciales de luz (SLMs, por sus siglas en inglés). Ambos son capaces de realizar operaciones matriciales a muy bajo coste en términos de energía y con muy poca disipación térmica. En estos circuitos, la información se codifica modulando los parámetros la luz (fase, amplitud o polarización), se procesa por interferencia y se lee mediante fotorreceptores. Constituyen el equivalente óptico de los Tensor Cores de los chips de NVIDIA, que soportan más del 80% de la carga computacional de una GPU durante la ejecución de un modelo de Deep Learning.
Interferómetros de Mach-Zehnder
El interferómetro de Mach-Zehnder (Mach-Zehnder interferometer, MZI) mide patrones de autointerferencia de un haz de luz coherente. El haz incide sobre un acoplador direccional, que divide la señal en dos brazos idénticos. Tras recorrer caminos de longitud similar, ambos brazos son recombinados por un segundo acoplador. Entonces interfieren entre sí de forma constructiva o destructiva en función de la diferencia de fase acumulada a lo largo de su recorrido. El detector final capta la intensidad resultante. La diferencia de fase puede manipularse desfasando la luz de uno sólo los brazos, modificando la longitud de cualquiera estos o variando la velocidad de la luz al atravesarlos (p.e. mediante la interposición de cristales).
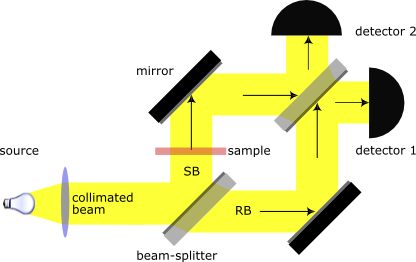
Figura 1. Esquema de un interferómetro de Mach-Zehnder, que puede utilizarse para multiplicar una matriz 2×2 por un vector. Los coeficientes de la matriz se cargan por el faseador marrón, que modifica el ángulo de fase de la luz en uno sólo de los brazos. Los coeficientes del vector inicial se codifican en la intensidad (o en el ángulo de fase, dependiendo del modelo) de la luz, antes de entrar en el interferómetro.
Computacionalmente, un MZI puede programarse para multiplicar un vector bidimensional por una matriz 2×2. Los valores del vector de entrada se codifican en la amplitud del haz de entrada, mientras que los coeficientes de la matriz determinan el desfase aplicado en uno de los dos caminos. La salida del interferómetro entrega directamente el resultado de la operación matricial. Matemáticamente, se expresa mediante la siguiente fórmula:
I_salida ∝ I_entrada * cos²(Δφ / 2)
donde I_salida e I_entrada son las intensidades de entrada y salida y Δφ es el ángulo de desfase.
Para escalar a matrices de mayor dimensión, deben construirse redes o mallas de MZIs interconectados. Estas configuraciones permiten realizar multiplicaciones matriciales arbitrarias de tamaño N×N.
Moduladores espaciales de luz (SLMs)
Un SLM (Spatial Light Modulator, modulador espacial de luz) es un dispositivo óptico que controla, píxel a píxel, la amplitud, fase o polarización de un haz de luz, formando una suerte de pantalla inteligente. Su principio se basa en materiales, típicamente cristales líquidos, que cambian su estructura interna al aplicarles un voltaje, modificando así la manera en que la luz atraviesa o se refleja en cada píxel. Cada punto actúa como una celda de control programable, alterando localmente las propiedades del haz.
Los SLM pueden ser transmisivos, cuando dejan pasar la luz, y los reflectivos (LCoS), cuando la reflejan tras modularla. Se utilizan en campos como la holografía dinámica, la óptica adaptativa en telescopios o las comunicaciones ópticas.
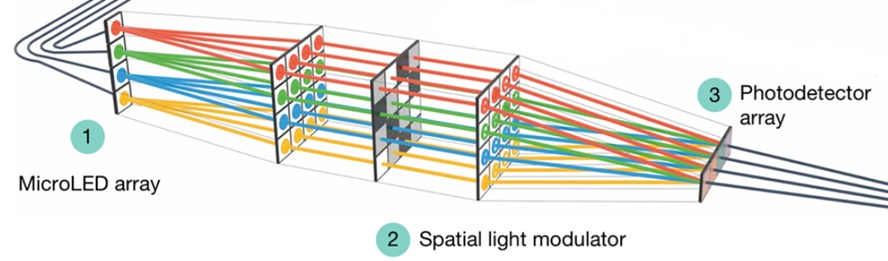
Figura 2. Esquema del funcionamiento de un modulador espacial de luz durante una multiplicación matriz-vector. La fila de LEDs representa a los componentes de un vector de entrada. La pantalla central modula la luz de conformidad con la matriz de pesos. Los fotodetectores del final miden los componentes del vector-resultado. Fuente: Microsoft Research.
En computación óptica, arquitecturas como AOC (All-Optical Computer) de Microsoft usan la pantalla SLM para representar físicamente la matriz de pesos de una red neuronal y realizar multiplicaciones matriz-vector. La implementación sigue este flujo:
–Representación del vector de entrada: Cada componente del vector se codifica mediante un LED individual, generando luz no coherente y no monocromática.
–Proyección en el SLM: El haz de cada LED se proyecta sobre una fila del SLM.
–Modulación por pesos: Cada píxel del SLM modifica la intensidad de la luz incidente según los valores de los pesos almacenados, realizando así una multiplicación óptica elemento a elemento.
–Integración y detección: La luz modulada se dirige hacia una fila de fotodetectores, donde se produce una suma de las contribuciones luminosas mediante interferencia aditiva. La operación combinada multiplicación-suma (MAC) es matemáticamente equivalente a un producto escalar.
–Lectura del resultado: Los fotodetectores convierten la intensidad luminosa total en señales eléctricas, obteniendo así los componentes del vector-resultado.
Implementación
Las dos tecnologías citadas fueron implementados exitosamente en 2025 en chips prototipo. Los MZIs fueron la base de los chips Meteor 1, construido por un equipo de especialistas en óptica de diversas instituciones chinas, y Envise, diseñado por la empresa estadounidense Lightmatter. Los SLMs, por su parte se convirtieron en el centro de otra nueva arquitectura óptica, AOC (Analog Optical Computing), creada por investigadores de Microsoft.
Cabe destacar que estos chips no son de naturaleza puramente óptica, sino más bien híbrida: La multiplicación matricial es realizada por la luz, pero las funciones no lineales, el control del flujo de instrucciones, la gestión de hilos de ejecución, así como la memoria (caché o externa) son implementados electrónicamente.
Obstáculos técnicos a resolver
Aunque las unidades fotónicas de 2025 se acercan teóricamente al rendimiento computacional de los tensor cores de las GPUs, sin embargo, todavía existen obstáculos técnicos para que la interferometría pueda realizar cálculos lineales con la misma eficiencia que los chips de silicio.
Entre los principales:
Falta de no linealidades y de memoria ópticas
En los citados modelos, la luz se limita a efectuar multiplicaciones matriciales. Las funciones no lineales (ReLU, GeLU, sigmoide), las celdas de memoria y los circuitos de control se implementan electrónicamente.
En la actualidad, algunos estudios proponen el uso de capas de grafeno para emular el comportamiento de un rectificador, si bien, a fecha de 2025, estos métodos están aun en fase experimental y no se han incorporado a ningún prototipo de chip óptico. Aun más experimental es el uso de memorias puramente ópticas, basadas en cavidades resonadoras.
Volatilidad de los componentes
A escala nanométrica, ninguna guía de onda ni interferómetro es idéntico a otro. Las pequeñas desviaciones de fabricación provocan diferencias de atenuación, ruido o acoplamiento de la luz.
Esta variabilidad física es intrínseca y tiene tres consecuencias críticas:
-Dificulta la producción masiva y escalable de chips fotónicos.
Deriva térmica
La deriva térmica (drift) se produce cuando los materiales se expanden o se contraen como consecuencia de variaciones en la temperatura, produciéndose desviaciones con ello en el camino óptico. Para compensarlo, los chips incorporan sensores térmicos y diseños insensibles a variaciones de calor, aunque las correcciones requieren recalibraciones periódicas.
Calibración
-El sistema es inherentemente inestable ante cambios ambientales (temperatura, vibración).
Ruido y precisión de las señales ópticas
Históricamente, el desarrollo de los computadores analógicos ha estado condicionado por dos limitaciones fundamentales: la susceptibilidad al ruido y la precisión finita en la representación de los datos.
En todo sistema físico, el ruido surge de causas elementales: fluctuaciones térmicas en los circuitos, corrientes de fuga en los detectores y, a escala microscópica, efectos cuánticos.
En la computación digital, este ruido puede aislarse mediante niveles lógicos discretos y corregirse mediante algoritmos de detección y corrección de errores.
En cambio, en un procesador analógico —donde la información se codifica de forma continua— el ruido se propaga y acumula a lo largo del cálculo, de un estadio al siguiente, como sucede con las fotocopias sucesivas de un documento, que degradan poco a poco los contornos y patrones gráficos del original.
El resultado es una pérdida progresiva de fidelidad que puede reducir la capacidad computacional efectiva del sistema, incluso por debajo de la de un autómata de estados finitos.
El ruido afecta también a la precisión en la conversión de las señales de analógico a digital (o viceversa). La resolución real de un conversor se mide en ENOB (Effective Number of Bytes), parámetro que cuantifica la resolución efectiva de la señal, y que es inversamente proporcional al ruido existente.
Por lo general, con la tecnología actual, los conversores ADC y DAC pueden alcanzar un ENOB de 7-8 bytes, lo que equivale a una resolución INT8. Aunque la luz puede representar números con más bits, la precisión de los detectores constituye un límite a la aritmética.
Sin embargo, para realizar un producto escalar de dos vectores (INT7 e INT11) de 16 componentes serían necesarios 20 bits:
20 = 7 + 11 + ln₂ (16)
Muy por encima de los 8 bits que en teoría permitiría una unidad óptica.
Lightmatter resolvió este límite parcialmente en Envise: mediante lecturas sucesivas a diferentes ganancias (factores de amplificación) del amplificador transimpedancia, reconstruyó resultados de 24 bits, posibilitando productos escalares de 128 componentes, a aritmética INT7 (pesos) e INT11 (activaciones).
Cuello de botella electro-óptico
El mayor obstáculo práctico para que los procesadores ópticos (OPUs) superen a las GPUs es la conversión entre dominios, realizada por los ADC/DAC. Estos componentes consumen una energía desproporcionada, añaden latencia y limitan severamente la frecuencia operativa. Mientras la sección óptica puede operar a decenas de GHz, los ADC/DAC la restringen a sólo 2-5 GHz.
Además, la energía consumida por un conversor escala exponencialmente con la resolución. Por ello, lograr alta precisión (12-16 bits) a velocidades de GHz resulta energéticamente inviable.
La consecuencia es que la electrónica ahoga la fotónica. La multiplicación óptica es extremadamente rápida y eficiente, pero la interfaz de conversión la ralentiza y consume la mayor parte de la energía. En 2025 fueron presentados dos mecanismos para aliviar este cuello de botella:
–Paralelismo óptico. Un mismo haz está conformado por múltiples canales (del orden de un centenar) que transportan información a diferentes frecuencias. Es el sistema empleado por los investigadores de Meteor 1, que usan para ello multiplexación WDM.
–Lecturas multi-ganancias. La misma señal óptica es procesada por el amplificador a diferentes ganancias (factores de amplificación), aumentando con ello la resolución de lectura. Sistema utilizado en Envise.
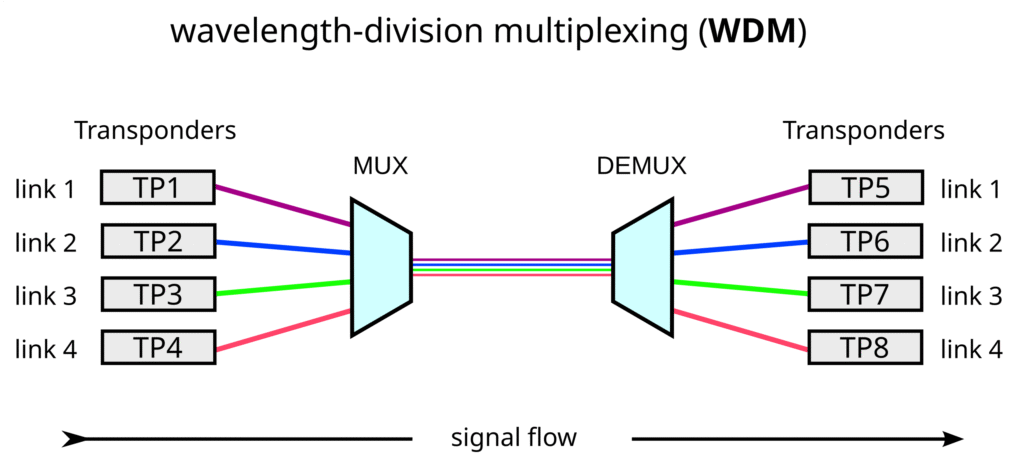
Figura 3. El multiplexado combina diferentes canales en una misma señal óptica. Es desmultiplexado realiza la operación contraria. En computación óptica, ello permite introducir paralelismo (un canal = un número), pero a costa de introducir el problema de la diafonía entre canales. Fuente: Wikipedia.
Diafonía
La diafonía —en inglés, cross-talk— es un fenómeno por el cual las guías de onda de los interferómetros no actúan como compartimentos estancos, sino que filtran luz (y con ello información) a las guías adyacentes, interfiriendo gravemente en el cálculo.
La diafonía también puede darse también entre diferentes canales dentro de una misma guía óptica. En este caso, la señal de un canal interfiere con longitudes de onda vecinas. Las fuentes de error incluyen, entre otras: dispersión de fase, variaciones en la transmisión entre longitudes de onda, o los efectos térmicos en los faseadores, entre otras.
Ausencia de un CUDA óptico
El ecosistema CUDA no es solo un lenguaje, sino un entramado de compiladores, bibliotecas (como cuDNN) y herramientas de optimización que permiten explotar todo el potencial de las GPUs.
Los chips ópticos carecen hoy de un entorno equivalente.
El coste de migrar el inmenso código existente hacia nuevas arquitecturas crea una inercia técnica difícil de superar.
La estrategia más realista para los fabricantes fotónicos es integrarse con los frameworks actuales: ofrecer “plugins” o “backends” para PyTorch o TensorFlow que permitan ejecutar, con cambios mínimos, las operaciones lineales en las OPUs.
Potencial disruptivo de la computación óptica
A pesar de los obstáculos descritos en la sección anterior, el rendimiento algunos prototipos ópticos se está acercando (en el año 2025) al los chips de silicio más avanzados. Las principales ventajas de la computación óptica híbrida sobre la puramente electrónica, pueden resumirse en los siguientes puntos:
Superior frecuencia del reloj
Paralelismo
Operaciones por segundo
Una unidad óptica del chip Envise ejecuta hasta 32.000 operaciones MAC por ciclo, mientras que Meteor 1 alcanza unas 27.000. En términos de operaciones aritméticas simples Meteor 1 logra un rendimiento teórico máximo de 2.560 TOPS, si bien probablemente utilizando una aritmética de baja profundidad (INT4).
Combinando la alta resolución de Envise con el paralelismo de Meteor 1, sería factible realizar operaciones matriciales en régimen de INT8 (el empleado la inferencia de los modelos de LLMs) a una frecuencia de unos 2.500 FLOPS, comparable a los 3.000-4.000 TFLOPS FP8 de NVIDIA. No obstante, el ruido analógico y las pérdidas de conversión reducen en la práctica dicho rendimiento.
Si los ingenieros consiguen aumentar aun más el número de canales (por ejemplo, de 100 a 500 longitudes de onda) de las unidades ópticas el rendimiento computacional de estas últimas podría superar finalmente al de los tensor cores de silicio.
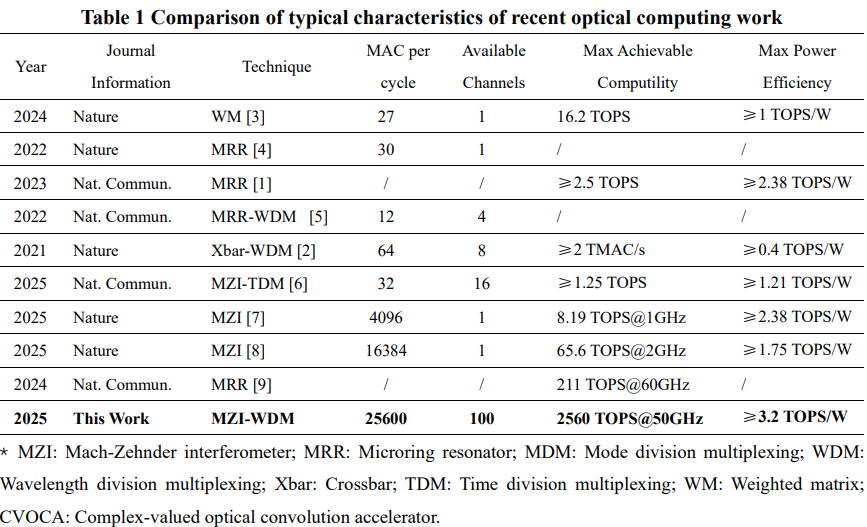
Figura 4. Tal y como se puede comprobar en esta tabla (referida al chip Meteor1), el crecimiento en el poder computacional de los chips ópticos en los últimos cuatro años ha sido exponencial, tanto en términos de TOPS como en MACs por ciclo del reloj. La eficiencia energética (TOPS/W, columna de la derecha) mejora de forma más gradual, aunque sostenida (x3-x8). Fuente: Parallel Optical Computing Capable of 100-Wavelength Multiplexing.
Eficiencia energética
Conclusiones
La computación óptica se encuentra en una encrucijada histórica similar a la que vivían las GPUs antes de 2012: dispone de un potencial teórico abrumador en eficiencia energética y throughput, pero adolece de una brecha crítica de madurez. Su evolución depende menos de ganar algunos TOPS adicionales que de resolver tres carencias fundamentales: un ecosistema software sólido, una calibración estable y una interfaz electro-óptica más eficiente.
El punto de inflexión llegará con un «momento Cireșan óptico»: un experimento reproducible y inapelable donde una OPU ejecute un modelo real como LLaMA o BERT con una ventaja de 5-10x en eficiencia energética frente a un H100, usando un stack de software accesible. Quien alcance ese hito no solo cuestionará la hegemonía de las GPUs, sino que alterará el equilibrio de poder en la industria del hardware IA y probablemente redefinirá la geopolítica mundial de semiconductores. Será el tema de nuestro próximo artículo.






