
Envise: la precisión de los bits lumínicos
Rubén Rodríguez Abril
Envise, el acelerador fotónico de Lightmatter, se acerca desafiante al rendimiento de las GPUs ejecutando multiplicaciones matriciales 128×128 en interferómetros ópticos. Este chip híbrido combina fotónica para el cálculo masivo y electrónica para control y memoria. Aunque opera con pesos y activaciones cuantizados a 7 y 10 bits, logra una precisión cercana a FP32 en modelos como BERT y ResNet, marcando un hito en la computación post-silicio.
Lightmatter, una empresa de computación fotónica formada en el año 2017 por egresados del MIT, presentó en el año 2025 un chip dotado de un tensor core fotónico denominado PTC (Photonic Tensor Core), que utiliza interferómetros como base de su arquitectura. El procesador demostró ser capaz de ejecutar satisfactoriamente versiones de BERT, ResNet, así como el algoritmo de aprendizaje profundo de Atari.
El chip tiene un diseño híbrido, de naturaleza óptico-electrónica. Las operaciones matriciales se realizan dentro del dominio óptico del PTC, mientras que la gestión de memoria, la comunicación con la CPU, la extracción (fetching) y envío (dispatching) de las instrucciones son realizados por circuitos electrónicos en silicio.
La multiplicación de matrices mediante interferómetros de Mach-Zehnder —base del funcionamiento del PTC— fue analizada en nuestro primer artículo sobre computación óptica, al que remitimos al lector interesado.
Arquitectura
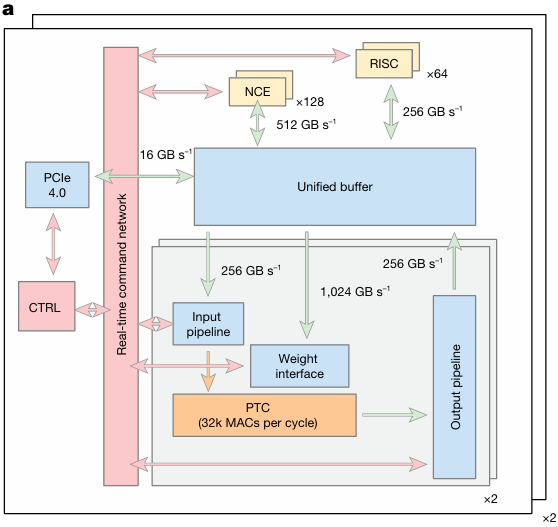
Figura 1. Esquema de la arquitectura del chip Envise. La unidad óptica (PTC) está coloreada en naranja. Las flechas rosadas señalan el flujo de control. Las flechas verdes, el flujo de datos. Fuente: Universal photonic artificial intelligence acceleration.
El diseño integra seis chips interconectados, cuya estructura interna se articula en los siguientes componentes principales:
–Orquestador (scheduler, CTRL): se comunica con la CPU a través de un bus PCI 4.0, reparte la carga de trabajo y las instrucciones entre las diferentes unidades del chip.
–Núcleo tensorial fotónico (PTC): ejecuta, vía interferómetros, multiplicaciones matriz-vector de 128×128. Su velocidad de procesamiento es de 32.000 operaciones MAC (multiplicación-acumulación) por ciclo del reloj.
–Búfer unificado: almacena las activaciones, los pesos activos y los pesos en espera de carga, actuando como un caché central de datos.
–Procedimientos de entrada y salida (pipelines): El procedimiento de entrada (input pipeline) lee los datos de entrada del búfer, los transforma en señales analógicas y los convierte en haces de luz de intensidad modulada para su procesamiento óptico. La interfaz de pesos (weight pipeline) hace lo propio con los pesos sinápticos, que son cargados en los faseadores de los interferómetros, que modulan el ángulo de fase. El procedimiento de salida (output pipeline) lee el resultado a través de los fotorreceptores, los amplifica, los digitaliza y las envía al búfer.
-Unidades aritmético lógicas NCE (Neural Compute Engines): ejecutan (en bfloat16) aquellas operaciones aritméticas no consistentes en multiplicaciones matriciales. Entre ellas las funciones no lineales, las reducciones y las operaciones de acumulación (en bfloat24) de resultados fotónicos. Funcionan como una unidad SIMD (una instrucción afecta a múltiples datos) con 128 vías paralelas.
-Núcleos RISC-V ejecutan instrucciones simples procedentes de CTRL encargándose de tareas de sincronización, gestión de interrupciones, calibración de los faseadores y otras funciones no aritméticas.
A grandes rasgos, puede decirse que el scheduler y los núcleos RISC-V piensan, los NCE calculan en silicio, y los PTC multiplican a la velocidad de la luz. Todos los circuitos son puramente electrónicos, salvo el PTC, que es óptico.
La aritmética ABFP
Los circuitos digitales del sistema operan con el formato bfloat16 (8 bits de exponente, 7 bits de mantisa). Sin embargo, debido a las limitaciones del plano analógico, todas las variables deben convertirse al formato cuantizado ABFP antes de ingresar al Photonic Tensor Core (PTC). Esta conversión se realiza mediante un proceso secuencial de normalización y cuantización:
–Normalización: Todos los valores de la matriz o el vector deben ser normalizados en el rango [−1,1]. Esto se logra identificando el coeficiente de mayor valor absoluto -la escala- y dividiendo todos los elementos entre este valor. La escala se almacena aparte como referencia para el reescalado posterior.
–Cuantización: Los números resultantes se reducen a enteros de 7 bits para los pesos y 10 bits para las activaciones. Para ello se deben escoger los bits más representativos de sus mantisas.
Los pesos y activaciones en formato ABFP se transforman después en señales analógicas mediante conversores digital-analógico (DAC). En la unidad fotónica:
-Las activaciones modulan la intensidad de la onda óptica.
-Los pesos controlan el ángulo de desfase introducido en uno de los brazos del interferómetro.
La salida óptica es capturada por un fotorreceptor, amplificada por un TIA (amplificador transimpedancia) y convertida a digital mediante un ADC (conversor analógico-digital), obteniendo un valor en el rango [−1,1] que posteriormente se reescala a bfloat16.
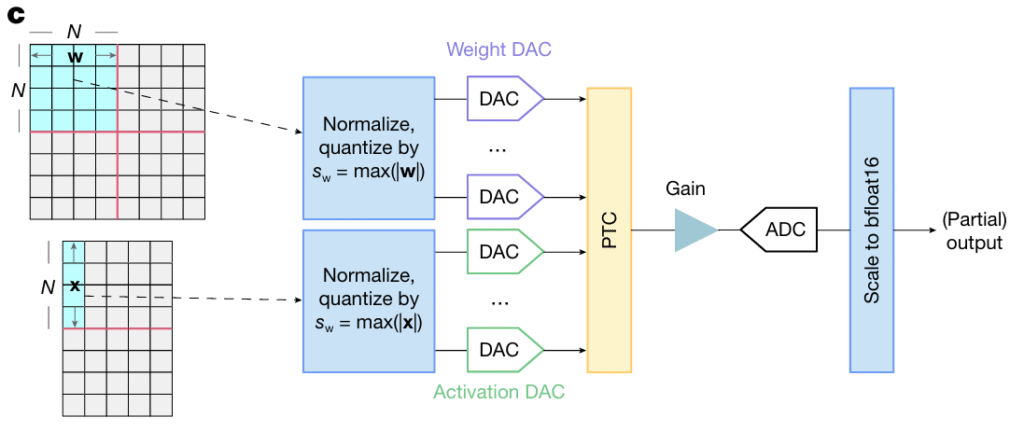
Figura 2. Esquema de los “pipelines” de entrada y de salida que flanquean la unidad óptica PTC. A la izquierda se muestran las matrices de pesos (w) y de activaciones (x) en formato bfloat16. La matriz de pesos tiene dimensión de 128×128, mientras que la de activaciones es de 128xK, donde K es el número de vectores a procesar. Sólo un vector de activaciones participa en cada multiplicación. Todas las variables se convierten al formato ABFP mediante operaciones de normalización y cuantización y tras ello se transforman en señales analógicas. Los pesos configuran los faseadores del interferómetro. Las activaciones modulan la intensidad de los haces de luz de entrada. Finalmente, el resultado de la multiplicación se digitaliza nuevamente y se reescala a bfloat16. Fuente: Universal photonic artificial intelligence acceleration.
En síntesis, dentro del PTC se usa ABFP mientras que el resto del procesador (NCE, RISC, buffer) opera en bfloat16. Ambos dominios, óptico y electrónico, se comunican mediante normalización y re-escalado.
Resolución de los resultados
La cantidad de bits necesaria para representar sin desbordamiento productos escalares de 128 componentes (las dimensiones de los vectores de la matriz) es de 24 bits. Esta cifra se obtiene de la siguiente suma:
-17 bits de los operandos (10 de activaciones, 7 de pesos).
-7 bits adicionales derivados del proceso de acumulación de 128 términos adicionales (7 = log2 128) en cada operación MAC (producto escalar).
Sin embargo, los conversores analógico-digital (ADC) usados en Envise poseen tan sólo 11 bits de resolución nominal y un ENOB (número efectivo de bits) de aproximadamente 9,8.
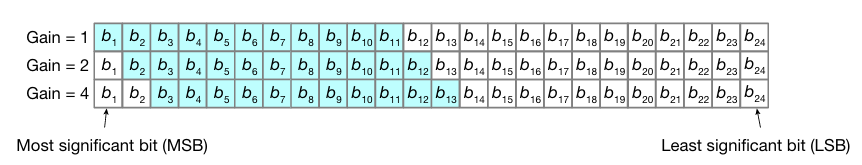
Figura 3. Incrementando la ganancia del amplificador se desplaza a la derecha el rango medible por parte del ADC. La ganancia funciona como una lupa electrónica que, en cada pasada, amplifica una parte distinta del número analógico contenido en la luz. Fuente: Universal photonic artificial intelligence acceleration.
La solución implementada por los ingenieros de Lightmatter consistió en modular la ganancia (factor de amplificación) del amplificador de transimpedancia (TIA), según se ilustra en la Figura 7:
-Con Ganancia = 1: El amplificador entrega la señal completa. El ADC captura los bits más significativos (MSB), mientras que los bits menos significativos permanecen por debajo del umbral de ruido.
-Con Ganancia = 2: La amplificación de la señal desplaza los bits de menor peso —anteriormente ocultos— dentro del rango medible del ADC, saturando sin embargo los MSB.
-Con Ganancia = 4: El proceso se repite, sacrificando los MSB ya saturados y permitiendo la captura de bits aún más débiles.
Cada nivel de ganancia permite leer una porción distinta del rango dinámico de la señal.
Combinando mediciones sucesivas, el procesador reconstruye un resultado de 24 bits efectivos a partir de varias pasadas de 11 bits cada una.
Una vez reconstruido el valor de 24 bits, este se convierte a bfloat16 mediante dos operaciones secuenciales: primero, una descuantización que divide el valor entero entre 2¹⁷ (implementada como un simple desplazamiento de bits de 17 posiciones); y segundo, un reescalado que multiplica por la escala común utilizada en la normalización inicial.
Eficiencia en inferencia
La mayoría de las GPUs actuales actúan en régimen de semiprecisión, utilizando operandos en formato FP16 y acumulación en FP32. Sin embargo, tal y como vimos en secciones anteriores, durante las operaciones matriciales Envise opera en ABFP y acumula en un formato de 24 bits que los autores del trabajo denominan ‘bfloat24’, aunque este no es un estándar de la industria sino una designación interna para su acumulador de 24 bits.
Esta diferencia fundamental obliga al nuevo procesador a trabajar con versiones cuantizadas o simplificadas de los modelos de deep learning. Aun así, durante las pruebas de evaluación, Envise demostró un rendimiento muy cercano al de los procesadores en FP32 en una amplia gama de modelos.
Una de las claves que explica este notable rendimiento es la implementación de la técnica de Entrenamiento Consciente de Cuantización (QAT). Mediante este método, los modelos se entrenan inicialmente en FP32, pero durante el aprendizaje se intercalan capas de cuantización que también introducen ruido real, reproduciendo las cualidades de ejecución de un hardware óptico. Así, el modelo aprende a tolerar las imprecisiones propias del cómputo analógico.
Al finalizar el entrenamiento, los pesos resultantes se reducen al formato bfloat16, optimizados para mantener su eficacia a pesar de la reducción de precisión.
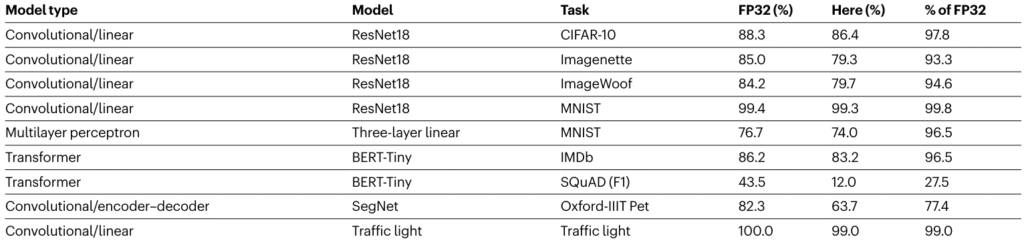
Figura 4. Comparación del rendimiento de Envise con procesadores de aritmética FP32 en diferentes modelos de visión artificial (redes convolucionales) y modelos de lenguaje (transformers). Fuente: Universal photonic artificial intelligence acceleration.
Conclusiones
Este trabajo representa un avance sustancial en la computación fotónica aplicada al deep learning, al demostrar que un procesador híbrido puede alcanzar precisión y rendimiento comparables a los sistemas digitales en modelos complejos sin modificaciones arquitectónicas específicas. La ejecución satisfactoria de modelos como ResNet y BERT, así como de algoritmos de aprendizaje por refuerzo -incluido el clásico DeepMind Atari-, este procesador marca un paso esencial en la computación post-transistor.
Aunque persisten desafíos de integración y eficiencia, este desarrollo consolida los cimientos para una nueva generación de hardware donde la luz y los electrones colaboran para superar los límites físicos y energéticos del cómputo convencional.






