RAG
Rubén Rodríguez Abril
RAG (“Retrieval-Augmented Generation”, Generación aumentada por recuperación) es un sistema de extracción de información que permite a los modelos de lenguaje acceder a información externa (SQL, vectores, web), incorporándola a su ventana de contexto. Los modelos más avanzados constituyen verdaderos meta-algoritmos: una nueva capa de NLP que se despliega por encima del modelo de lenguaje.
Dentro de los modelos de lenguaje se distingue entre memoria paramétrica, que está almacenada en los propios pesos sinápticos del modelo, y memoria no paramétrica, que se localiza externamente en otras ubicaciones, como bases de datos SQL o la propia web. Los mecanismos mediante el cual el modelo de lenguaje accede a esta memoria no paramétrica y elabora cadenas de texto a partir de la misma se denominan generación aumentada por recuperación, o, en lengua inglesa, Retrieval Augmented Generation (RAG).
Por lo general, estas técnicas suelen involucrar a dos redes:
-Una red auxiliar, denominada recuperador, se encarga de recopilar información en base a la consulta realizada por el usuario.
-La red principal, llamada generador, elabora la respuesta al usuario en base a su propia memoria interna (paramétrica) y a la información proporcionada por el recuperador.
Recuperación de información
Los modelos de recopilación de información pueden funcionar según dos esquemas diferentes:
–Esquema probabilístico: Devuelve documentos en función de la frecuencia de palabras clave contenidas en el texto. Uno de los modelos más usados BM25 (Best Match 25), que usa coincidencias exactas.
–Esquema denso: Emplea embeddings textuales para etiquetar las diferentes partes del documento y para codificar las consultas del usuario. Se seleccionan los pedazos de documento cuyos embeddings sean más cercanos semánticamente a la consulta del usuario. Es el esquema usado por DPR (Dense Passage Retrieval) y otros algoritmos de búsqueda vectorial, cuyo funcionamiento bosquejamos a continuación.
Bases de datos vectoriales
El trabajo “Dense Passage Retrieval for Open-Domain Question Answering” (2020) fue uno de los primeros en usar espacios de representación comunes para localizar pasajes con información relevante en una base de datos externa.
En el esquema usado por los autores, el recuperador tiene a su disposición una colección de D documentos, d1, d2… dD. Cada uno de estos documentos es dividido en pasajes textuales de igual longitud. Con ello se obtiene corpus textual C de M pasajes C = {p1, p2…pi}. Cada pasaje pi, a su vez, es una sucesión de tokens wi1, wi2, wi3….
El objetivo del recuperador es encontrar, dentro del corpus, los k pasajes de texto que mayor relevancia tengan respecto al contenido de la consulta. Por lo general, M es un número bastante grande (21 millones en el experimento original), mientras que k suele ser pequeño, del orden de 20-100.
Todos los pasajes del corpusasí como las consultas de usuarios son representados por vectores en un espacio semántico compartido. Para ello, se emplean dos codificadores BERT: uno para los pasajes, que reduce cada uno de ellos a un vector denso a través del token especial [CLS], y otro para la consulta del usuario. El recuperador selecciona los k pasajes cuyos embeddings sean más cercanos geométricamente (en términos de similaridad de coseno) al de la consulta del usuario. Algebraicamente, el procedimiento se expresa así:
q(x) = BERTQ(x)
p(pi) = BERTP(pi)= q(x)·p(pi)
donde x es la consulta del usuario, pi los diferentes pasajes, y q(x) y p(pi) los respectivos codificadores. La similaridad entre vectores se determina a partir de su producto escalar, que en un espacio vectorial normalizado equivale a la similaridad de coseno.
La búsqueda de información se transforma así en una variante del algoritmo de los k vecinos más cercanos (k-NN). En el ámbito del Aprendizaje Profundo, la biblioteca FAISS (Facebook AI Similarity Search) es una de las más utilizadas para esta tarea, diseñada para las búsquedas a gran escala. Su métrica primaria es L2, si bien permite también el uso de la similaridad de coseno. Las distancias entre vectores son calculadas mediante multiplicaciones matriciales que pueden ser paralelizadas en múltiples GPUs. Entre las bases de datos vectoriales más conocidas podemos citar ChromaDB o Qdrant.
RAG
El término Retrieval-Augmented Generation designa genéricamente a aquel conjunto de técnicas en cuya virtud un modelo de lenguaje utiliza información externa, no almacenada en sus pesos sinápticos, para responder a la consulta de un usuario. El trabajo “Retrieval-Augmented Generation for Large Language Models: A Survey” clasificó a estas técnicas en tres grupos diferentes: RAG original (Naïve RAG), RAG avanzado (Advanced RAG) y RAG modular (Modular RAG).
RAG original (Naïve RAG)
El término Retrieval-Augmented Generation designa genéricamente a aquel conjunto de técnicas en cuya virtud un modelo de lenguaje utiliza información externa, no almacenada en sus pesos sinápticos, para responder a la consulta de un usuario. El trabajo “Retrieval-Augmented Generation for Large Language Models: A Survey” clasificó a estas técnicas en tres grupos diferentes: RAG original (Naïve RAG), RAG avanzado (Advanced RAG) y RAG modular (Modular RAG).
-Un codificador (passage encoder) convierte los pasajes del corpus textual en representaciones densas, que son almacenados en una base de datos especial.
-Otro codificador (query encoder) transforma la consulta del usuario en un vector.
-Un recuperador (retriever) escoge a aquellos k pasajes cuyos vectores sean más similares, en términos geométricos, al de la consulta. Una función de similaridad puntúa a cada pasaje. Consiste en el exponente de la similaridad de coseno del vector-consulta q(x) con el vector-documento q(zi) en cuestión, esim(q(x),p(z))
-Un generador (generator) crea la cadena de respuesta a partir de los documentos extraídos y de su propia memoria paramétrica. Por lo general es un transformer, pero puede ser cualquier modelo seq2seq (como por ejemplo, una red neuronal recurrente). El texto de los pasajes es agregado a la ventana de contexto.

Figura 1. Diagrama de funcionamiento del algoritmo original de RAG. A la izquierda del todo, en diferentes colores, se representan las consultas del usuario. A la derecha, las correspondientes respuestas.
El generador y el recuperador son preentrenados por separado. El afinamiento tiene lugar conjuntamente, afectando a todo el modelo, realizándose el proceso de retropropagación de fin a fin.
El procedimiento a través del cual la información de los diferentes documentos es combinada para generar la respuesta se denomina marginalización. Puede tener lugar a través de dos enfoques diferentes: RAG-Sequence y RAG-Token.
RAG-Sequence
El generador produce, mediante un algoritmo de búsqueda de haz, N cadenas paralelas para cada uno de los documentos, que reciben el nombre de hipótesis de respuesta. Se obtiene así un conjunto de hipótesis YZ para cada documento, del que se deriva un conjunto global Y.
Todas las hipótesis del conjunto global deben ser puntuadas. La puntuación se obtiene multiplicando la ponderación del documento por la probabilidad de la cadena (que como el lector recordará, se deriva de la probabilidad de sus tokens). Si alguna hipótesis no aparecía en el haz de algunos documentos se la hace pasar adelante (forward pass) con dichos textos, con el objetivo de asignarle probabilidad. Con esto aseguramos que las hipótesis generadas a partir de un documento puedan ser valoradas en el marco de otros conextos.
La hipótesis más puntuada es la devuelta al usuario.
RAG-Token
La ponderación entre los diferentes documentos se realiza token a token. En cada paso de creación de la nueva cadena, el generador produce una distribución probabilística de tokens para cada uno de los documentos. Y tras ello se procede a ponderar las funciones de probabilidad. Con ello obtenemos la distribución de tokens definitiva:
η(zi|x) = esim(q(x),p(z))
p(yi|x,z,y1:i-1) = Ση(zi|x)·p(yi|x,z,y1:i-1)
donde p(yi) es la probabilidad asignada al token yi en el paso i, z es cada documento y x es la consulta del usuario.
El esquema primitivo de RAG presentaba inconvenientes relacionados con la falta de alineación con la consulta del usuario, la baja precisión, la aparición de alucinaciones o incoherencias en la cadena de salida como consecuencia de la utilización de documentos con información contradictoria. Estas debilidades motivaron el desarrollo de variantes más refinadas, como el RAG avanzado, que analizaremos a continuación.
RAG avanzado
Durante los primeros 2-3 años desde la publicación del trabajo fundacional sobre RAG, los avances en los algoritmos de extracción de información por parte de los modelos de lenguaje fueron más bien escasos. Sin embargo, la aparición de ChatGPT y la necesidad de prevenir las alucinaciones en los nuevos chatbots motiviaron la aparición, a partir del año 2023, de nuevos mejoras en el algoritmo. Estas mejoras se sustanciaron en la agregación de dos fases nuevas al algoritmo: una etapa anterior a la recuperación de la información (Pre-Retrieval) y otra posterior (Post-Retrieval) a la misma.
Mejoras en la fase de preextracción
Se centran en mejorar la calidad de los datos indexados. Se incluyen la adición de metadatos estructurales (como fechas, capítulos, secciones) o la depuración de incoherencias dentro de los textos, entre muchas otras.
Mejoras en la fase de extracción
Fundamentalmente, afectan a las representaciones vectoriales de los textos. Las optimizaciones de articulan en dos vías complementarias:
-Preentrenamiento: El codificador BERT usado para crear los embeddings documentales es preentrenado para actuar en dominios específicos, como el médico o el matemático. Los datos necesarios para el preentrenamiento consisten en pares pregunta-respuesta generados a partir de un texto y pueden ser proporcionados por modelos de lenguaje como GPT-3.5-turbo.
–Embeddings dinámicos: A diferencia de lo que sucede con los embeddings estáticos, estos mecanismos de codificación adaptan y modifican sus representaciones al contexto de la consulta.
Mejoras en la fase de postextracción
En esta última etapa, el modelo de lenguaje integra la información recuperada con su propia memoria paramétrica para crear la respuesta. Sin embargo, la incorporación directa de múltiples documentos al contexto puede introducir ruido o provocar el desbordamiento de la ventana de atención. Por ello, se introducen técnicas de procesamiento adicional:
a) Reordenación del contexto. Una vez que los k documentos más relevantes han sido seleccionados, su puntuación es recalculada por una red auxiliar. Algunos algoritmos priman la diversidad de fuentes mientras que otros colocan el documento más relevante al inicio y al final de la ventana de contexto.
b) Compresión del prompt. Se basan en la reducción de la longitud del prompt, con el propósito de impedir que se produzcan desbordamientos en la ventana de contexto. Estas técnicas incluyen el resumen de textos en diferentes granularidades, el filtrado de contenido no esencial y la ponderación de frases según su importancia, entre otras.
RAG modular
En los modelos más avanzados, el procedimiento se estructura en módulos especializados en tareas específicas. Entre los más comunes podemos citar lo siguientes:
–Búsqueda (Search Module): Es el encargado de recuperar la información relevante para la consulta de que se trate. Puede conectarse a bases de datos vectoriales, motores de búsqueda o documentos estructurados (p.e. PDFs).
–Memoria (Memory Module): Su misión es almacenar información y gestionar su persistencia a lo largo de todo el procedimiento. No sólo se almacenan los documentos externos, sino también información relacionada con la ventana de contexto, como las cadenas de razonamiento o los diálogos anteriores con el usuario.
–Fusión (Fusion Module): Genera la cadena de respuesta definitivo, combinando la información procedente del exterior con su propia memoria paramétrica y la consulta del usuario.
–Enrutamiento (Routing Module): Es el “director” del procedimiento. Señala cuáles son los próximos módulos a activar, qué datos concretos deben de extraerse y cómo deben almacenarse (bases de datos vectoriales, relacionales, etc…).
–Predicción (Prediction Module): Contiene el propio modelo generativo.
Estos módulos pueden combinarse de diferentes maneras para crear el pipeline (procedimiento) definitivo. Por ejemplo, los modelos RAG original y RAG avanzado siguen el esquema búsqueda-fusión-predicción.
Usualmente, suelen utilizarse frameworks como LangChain, Haystack, LlamaIndex o DSP para coordinar las diferentes partes del proceso.
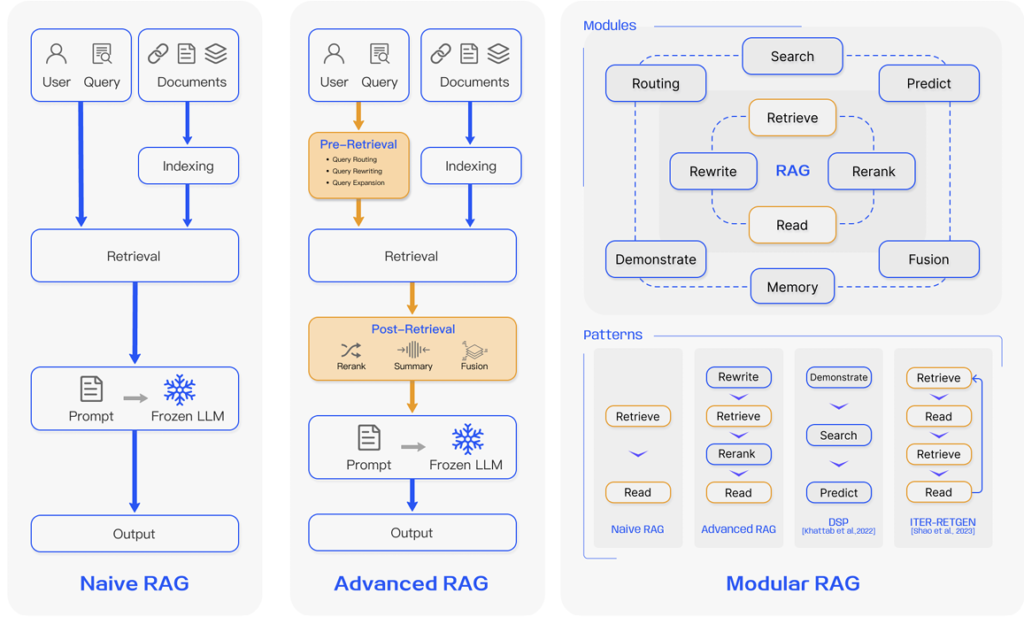
Figura 2. Comparación entre los tres esquemas. Fuente: “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks”.
Perspectivas de futuro
La aparición de la RAG ha constituido una progresión importante en el desarrollo de los modelos de lenguaje, al permitirles superar por fin las limitaciones de su propia memoria paramétrica. Gracias a las nuevas técnicas, pueden integrar dentro de su pipeline (flujo operativo) información procedente de fuentes diversas como bases de datos relacionales (SQL), almacenes vectoriales, grafos de conocimiento, así como la propia world wide web.
Con todo, es éste un ámbito en pleno desarrollo, en el que hay diferentes líneas de investigación en marcha. Entre ellas destacan la combinación de recuperación externa y afinamiento; la recuperación de información por parte de un modelo de lenguaje de su propia salida; la posible existencia de leyes de escala que afecten a RAG; así como el surgimiento de nuevos modelos de enrutamiento dinámico que posibilitan al modelo determinar cuándo y qué información recuperar. Además, destaca la aparición de nuevos modelos de RAG multimodal que permiten extraer no sólo texto sino también imágenes, audio o código.
RAG ya no es un simple añadido funcional, sino que se configura como una capa estructural equiparable a los modelos de lenguaje, que modula el comportamiento de estos últimos, les provee de memoria ampliada y permite su especialización sin un costoso procedimiento de entrenamiento.