
Mistral AI
Rubén Rodríguez Abril
Mistral AI, fundada en 2023, es la alternativa europea y francesa a los avances en procesamiento de lenguaje natural liderados por EE. UU. y China. Algunos de sus modelos, como Mistral 7B, Codestral, y Mathstral han destacado en programación y razonamiento matemático. La empresa es muy cooperativa con el gran público, ofreciendo gratuitamente la descarga de los pesos sinápticos de muchos de sus modelos, fomentando así el acceso abierto a la tecnología avanzada de IA.
Introducción
La francesa Mistral AI es, en la fecha en que se escribe este artículo (Septiembre de 2024), la empresa europea más influyente en materia de los grandes modelos de lenguaje. Fue fundada en Abril de 2023 por tres antiguos trabajadores del sector tecnológico estadounidense: Arthur Mensch (DeepMind), Timothée Lacroix (Meta) y Guillaume Lample (laboratorio de investigación de Google). En Septiembre de 2023 publicó su primer modelo de lenguaje, Mistral-7B, al que siguieron un sistema de expertos y varias secuelas especializadas en código y razonamiento matemático. Algunos de ellos, serán explorados en las secciones subsiguientes de este artículo.
Mistral 7B
El primer modelo presentado por la empresa, Mistral 7B, contaba, como su propio nombre sugiere, 7 mil millones de parámetros. Su arquitectura es prácticamente similar a la del transformer original de 2017, con algunas particularidades que analizaremos a continuación, como la atención GQA (GQA, Grouped-Query Attention) o la atención de ventana deslizante (SWA, Sliding Window Attention). Por lo demás, el modelo tiene 32 capas y tiene una dimensión de 4096. En cada una de las capas hay 28 cabezas de atención, de 128 parámetros cada una.
Atención agrupada (GQA)
Tal se vio en nuestro artículo dedicado a los transformers, en cada capa las unidades de atención se dividen en varias cabezas. A cada cabeza se le asigna una parte del hiperespacio semántico en el que se despliegan, como vectores, los tokens. Algunas de estas cabezas se especializan en detectar patrones gramaticales o semánticos, mientras que otras tienen en cuenta, fundamentalmente, la posicional. Cada cabeza está dotada de su propia matriz de atención, que se calcula a partir de tres matrices diferentes, denominadas Q (query, consulta), K (key, clave) y V (value, valor).
En cada cabeza, las citadas matrices toman la forma:
Qi = XiQQ
Ki = XiKK
Vi = XiVV
donde i es el número de cabeza y XiQ, XiK, XiV, las matrices de proyección, que crean versiones de las matrices consulta, clave y valor para cada cabeza. En la atención multicabeza, hay versiones de todas estas matrices para cada cabeza. En un esquema multiconsulta, las matrices XiK y XiV son compartidas por todas las cabezas. Finalmente, en la atención agrupada, grupos de cabezas (pero no todas ellas), comparten las matrices XiK y XiV. En la imagen se detallan estos esquemas con mayor claridad:
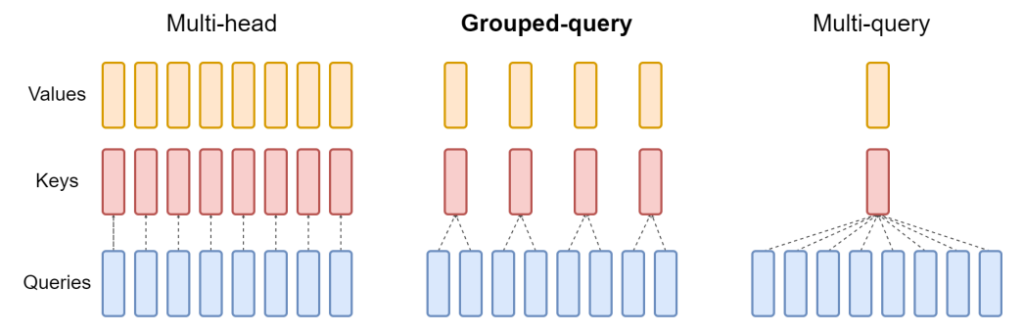
Figura 1: En la atención multi-cabeza hay una versión de Qi, Ki y Vi para cada cabeza. En la atención agrupada, varias cabezas comparten la misma Ki y Vi, mientras Qi sigue conservando su individualidad en cada una de ellas. Finalmente, en la atención multi-consulta todas las cabezas comparten Ki y Vi. Fuente: GQA: Training generalized multi-query transformer models from multi-head checkpoints.
Atención de ventana deslizante (SWA)
La ventana de contexto (es decir, el tamaño de la entrada inicial) de Mistral 8B es de 8.192 tokens. Es un número muy elevado, del que resulta una matriz de atención de dimensión 8.192×8.192. Su multiplicación por una matriz V de valores resulta en la necesidad de realizar 8.192×8.192×4096 operaciones de acumulación adición. Por comparación, un núcleo tensorial (Tensor Core) de NVIDIA A100 sólo puede realizar una multiplicación de 16x8x16 cada ciclo del reloj.
Para reducir la sobrecarga de la GPU, muchos modelos de lenguaje, como Mistral, anulan todos los componentes de la matriz de atención, salvo una pequeña ventana consistente en los elementos situados en la diagonal y adyacentes a la misma. La longitud horizontal de esta franja se denomina anchura de la ventana.
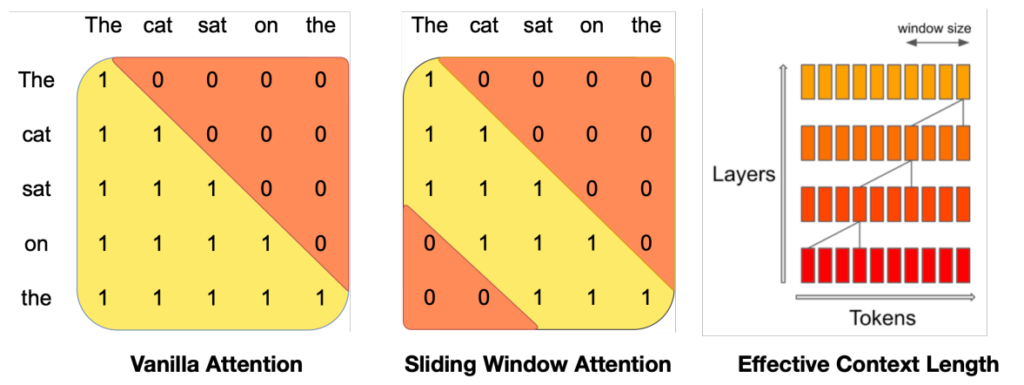
Figura 2. A la izquierda se muestra una matriz de atención dotada de una máscara ordinaria. En el centro, una ventana de tamaño tres. A la derecha se muestra cómo la información se transmite hacia los tokens de la derecha, conforme pasamos de capa en capa, cuando la ventana es de tamaño 4. Fuente: Mistral.
En Mistral 7B, el tamaño de la ventana es de 4096 tokens.
Fragmentación (chunking) del prompt
En todas las capas/módulos de un transformer, la matriz de entrada tiene un tamaño de nxd, donde n es el número de tokens y d la dimensión del modelo. La matriz puede ser entendida, pues como una cadena de n tokens/vectores de d componentes cada uno.
Con el objetivo de ahorrar memoria, en Mistral 7B, esta cadena de entrada es fraccionada en pedazos de k tokens, donde k es el tamaño de la ventana. Los pedazos ingresan en el núcleo tensorial para ser multiplicados por sectores de la matriz de atención, en el modo señalado en la imagen.
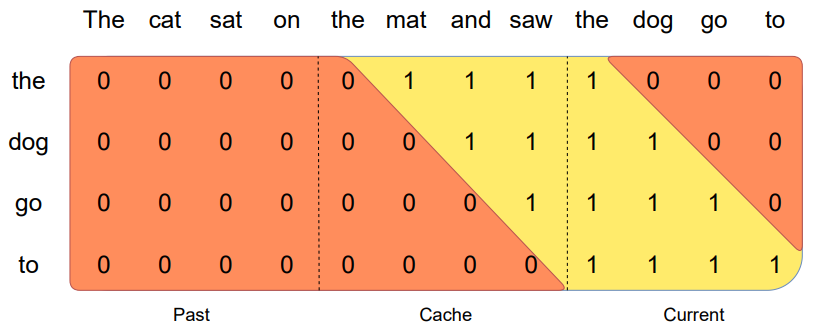
Figura 3. La cadena ya producida por el transformer se divide en pedazos del mismo tamaño que la ventana (en este caso, cuatro). Para el cálculo del nuevo token sólo es necesario que ingresen en la GPU los dos últimos pedazos. El primero de ellos se corresponde con los tokens recién producidos (“the dog go to”). Y el segundo, que se guarda en la caché, con los cuatro tokens inmediatamente anteriores “the mat and saw”. Fuente: Mistral.
Entrenamiento y resultados
Aunque el artículo original de Mistral nada dice al respecto, es de suponer que su modelo fundacional fue pre-entrenado con fuentes públicas como Google Crawl o Wikipedia. Para afinar el modelo, con el objeto de que fuera capaz de seguir instrucciones, fueron utilizadas las bases de datos públicas de Hugging Face.
El entrenamiento fue seguido utilizando GPUs A100 y H100.
Los resultados de la versión afinada Mistral 7B en las competiciones de Chatbot Arena fueron superiores a las de Llama 2, en sus versiones 7B y 13B, tnato en MMLU (comprensión multitarea), conocimiento del mundo o comprensión lectora.
Mistral 8x7B (Mixtral)
Se trata de una mezcla de expertos (Mix of Experts, MoE), esto es, de varias redes (en este caso, 8) que trabajan paralelamente entre sí y cada una de las cuales está entrenada en una base de datos y una tarea determinadas (p.e. matemáticas, programación, traducción a máquina…). En el transformer original, cada módulo estaba constituido por una unidad de atención que venía seguida de una mini-red orientada hacia adelante. En Mixtral, hay 8 mini-reds dispuestas paralelamente. Y cada una de ellas está especializada en una tarea determinada. Para cada token (y en cada capa), un router elige dos de estas redes expertas. Y la salida de éstas últimas es combinada.
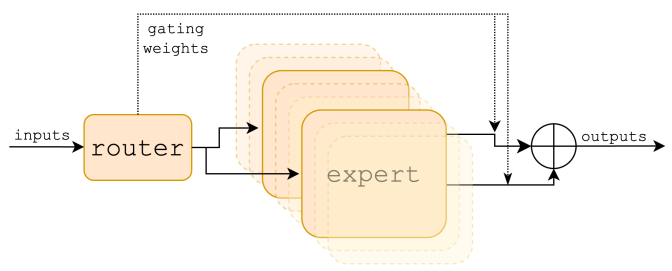
Figura 4. Una suerte de mecanismo de compuerta, consistente en pesos sinápticos, determina qué par de redes atravesara la información de entrada. La salida de los dos expertos es combinada.
Matemáticamente, el mecanismo de compuerta consiste en una capa lineal, dotada de 8 neuronas, acompañada de una función softmax, que atribuye puntuaciones G(x)i a cada uno de los expertos:
G(x)= softmax(Top2(x·Wg))
donde Wg es la matriz de pesos y Top2 pone a menos infinito los logits obtenidos por los expertos de menor puntuación (menos infinito se transforma en cero, tras aplicar la función softmax).
La información se enruta hacia las dos redes que hayan tenido puntuación G(x) no nula y atraviesa las mismas. Finalmente las dos salidas Ei(x) de los expertos se ponderan del siguiente modo:
ΣG(x)i·Ei(x)
Mixtral usa SwiGLU (ya descrita en nuestro artículo dedicado a PaLM) como función Ei(x) de expertos.
Los autores del artículo realizaron interesantes estudios acerca del funcionamiento interno de la función de enrutamiento. Y descubrieron que, contrario a nuestra intuición, las diferentes redes de expertos no parecen especializarse en determinadas materias, sino que todas ellas tienden a activarse en igual medida en las diferentes tareas que realiza el modelo. Particularmente, midieron estadísticamente el comportamiento del router en las capas 0 (inicial), 15 y 31 (final) del modelo. Y sus resultados son los mostrados en la imagen.
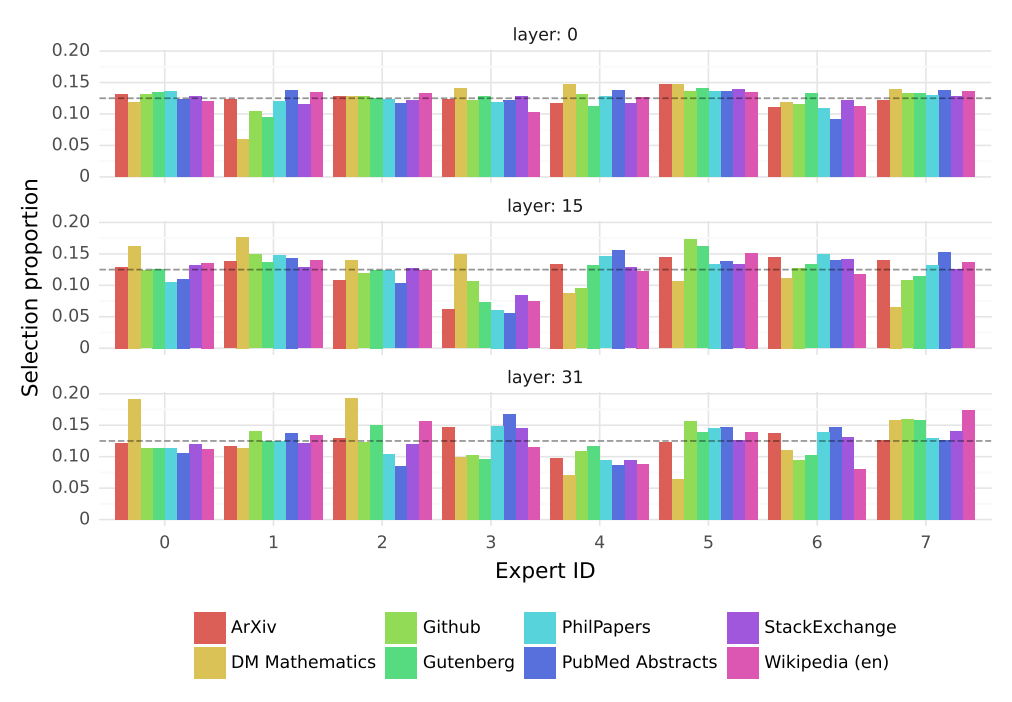
Figura 5. En la imagen se muestran las tasas de activación de los expertos (números del 0 al 7) en diferentes materias. La distribución es uniforme. Únicamente en matemáticas parece haber una ligera asimetría. Fuente: Mixtral.
El comportamiento del router también fue analizado token por token en programación de código, redacción de textos en inglés y matemáticas, obteniéndose resultados interesantes.

Figura 6. En la fila superior se muestra el comportamiento del router en tareas de programación. Así, en la capa 31, un experto (en amarillo) se encarga de gestionar los tokens de identación, mientras que otro (en rosa) gestiona las palabras reservadas. Dado que en Python cada identación supone una subida en la escalera de recursión, el router (que es una simple capa densamente conectada) parece llevar la cuenta de la “profundidad recursiva” de cada línea. Abajo del todo, tratándose de textos en lengua inglesa, se observa que en todas las capas, el router es capaz de agrupar tokens en palabras. Fuente: Mixtral.
Como segunda (aunque menor novedad) de Mistral, se encuentra la agregación de dos siguientes guardarraíles (guardrails) que controlan el comportamiento del modelo desde el exterior:
a) El primer de ellos consiste en la prefijación del suguiente prompt al inicio de cada ventana de contexto: “Always assist with care, respect, and truth. Respond with utmost utility yet securely. Avoid harmful, unethical, prejudiced, or negative content. Ensure replies promote fairness and positivity”.
b) El segundo, en la moderación de contenido con autorreflexión. El modelo es capaz de determinar eficazmente qué prompts del usuario son dañinos.
En total, Mixtral está dorada de 47B parámetros en total (parámetros globales), pero sólo 13B son utilizados en la inferencia (parámetros activos). Su ventana de contexto es de 32k tokens, y supera a Llama 2 70B y GPT-3.5 en varias pruebas de referencia, en matemática, generación de código y tareas multilingües.
Codestral
Codestral es un modelo de lenguaje creado para asistir a desarrolladores en más de 80 lenguajes de programación como Java, Python o Bash. Tiene una arquitectura de 22 millones de parámetros y ha sido afinado para realizar tareas de programación con gran precisión. Utiliza la técnica de “rellenar en el medio” y es accesible a través de una API.
Codestral Mamba es la secuela del modelo anterior, y está basada en la arquitectura Mamba2. Ha sido entrenado para redactar secuencias de código infinitas utilizando un tiempo lineal (es decir, proporcional a la longitud de la cadena producida) y está dotado de amplias capacidades de razonamiento.
Mathstral
Producido en colaboración con el Proyecto Numina, es un modelo de lenguaje afinado para realizar razonamientos de tipo matemático. Ha obtenido alta puntuación en evaluaciones (benchmarks) del sector como MATH (56,6%) o MMLU (63,47%).







