2.1 - Redes neuronales y tensores
En los orígenes históricos del Deep Learning la inspiración desde la neurociencia estaba muy presente y es por ello que se utilizaban términos como «redes», «neuronas», «pesos sinápticos», etc… Aunque dichos términos siguen en uso, es posible reducir nuestros modelos a simples operaciones de Álgebra Lineal. Afirmamos previamente que una red neuronal puede ser reducida a un conjunto de operaciones con tensores y ahora vamos a demostrarlo.
Función de excitación
Si habéis ojeado los artículos sobre redes neuronales sabréis que la acción de una capa neuronal se divide en dos operaciones: la función de excitación y la función de activación.
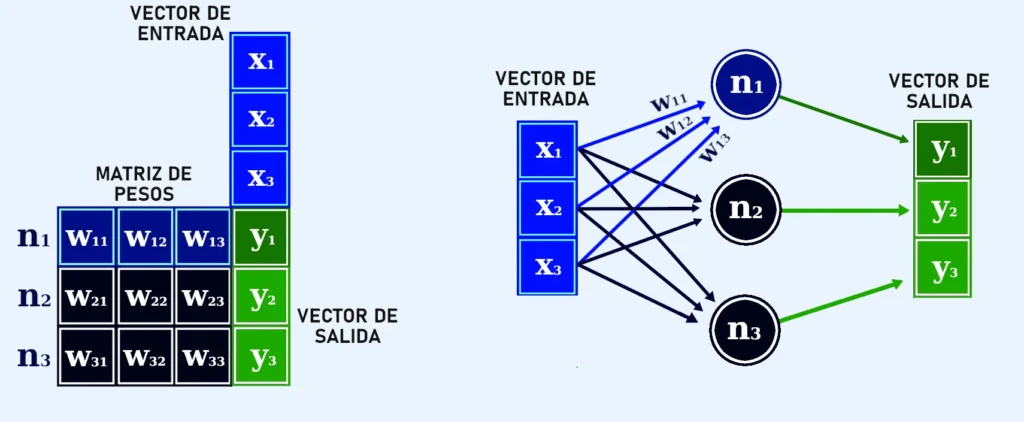
Pongamos un caso sencillo en que el input con el que se alimenta la red es un vector de entrada X unidimensional. Como se ve en la imagen, la función de excitación es equivalente al producto entre dicho vector de entrada y la matriz W que guarda los pesos de cada neurona de la capa. Cada celda de dicha matriz de pesos representa una conexión entre un valor del vector de entrada y una neurona.
Esta representación es válida para todas las capas de la red y también cuando el input de entrada es una imagen, es decir, un tensor de dos ejes. Y es que el procedimiento habitual es reducir todo tensor de entrada a un vector unidimensional.
Régimen lineal
Es muy habitual que al resultado de la función de excitación se le sume un valor constante llamado sesgo. La totalidad de esta suma será a su vez el argumento de la función de activación, que es la que aporta la no linealidad a la capa neuronal. Téngase en cuenta que los valores de entrada pueden ser muy cercanos a 0 y por tanto apenas existiría desplazamiento de la función por el eje x. La utilidad de este sesgo es permitir ese desplazamiento y ampliar por tanto el espectro de posibles resultados.
La función de excitación (término muy en desuso) más el sesgo es lo que en la bibliografía especializada se ha venido denominando régimen lineal, en contraposición a la función de activación que le sigue.